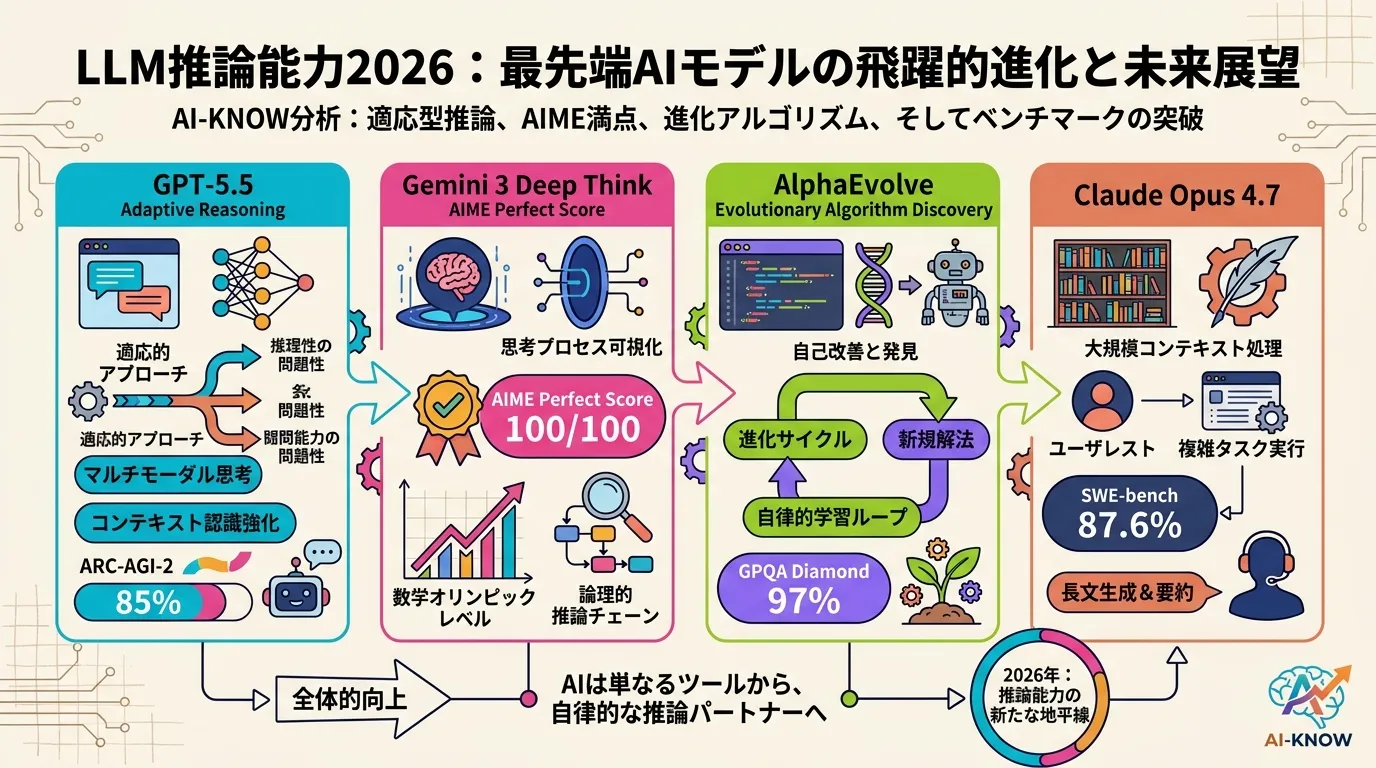
思考の連鎖(Chain-of-Thought)
思考の連鎖(Chain-of-Thought, CoT)は、LLM が最終回答を出す前に中間推論ステップを明示的に生成するプロンプト技法・訓練手法。“Let’s think step by step” に代表されるプロンプト CoT から、o1 系の RL による内部 CoT まで幅広い実装がある。
2026 年は Latent-GRPO など埋め込み空間での推論(潜在推論)が登場し、トークン出力なしで CoT に相当する精度向上を実現しつつある。中間ステップのハルシネーション抑制が主要研究課題。
※ このカードは ai-theme-roundup が記事生成時に自動生成した stub です。要補完。