LLM 推論能力の現在地 2026 — GPT-5.5 / Gemini 3 Deep Think / AlphaEvolve を比べる
AIME 満点・IMO 金メダル・ARC-AGI-2 85%——推論モデルの最前線が 2026 年に塗り替えた座標を整理する
2026 年、LLM の「推論」がついに測れるようになった。MMLU や HumanEval はフロンティアモデルが 90% 超で飽和し、差別化指標として機能しなくなって久しい。代わりに台頭したのが AIME(数学競技予選)・GPQA Diamond(博士レベル科学問題)・ARC-AGI-2(抽象的規則発見)といった「人間エキスパートすら苦労する」ベンチマーク群だ。
しかし「最も賢いモデルはどれか」という問いは単純な順位表では答えられない。推論モデル のアプローチは少なくとも 3 つの流派に分化している——深思考(Deep Think)、進化的アルゴリズム探索(AlphaEvolve)、そして**強化学習による推論内面化(RL推論)**だ。本記事はその 3 軸を整理し、ユースケース別の選択指針を示す。
現状の主要プレイヤー / 選択肢
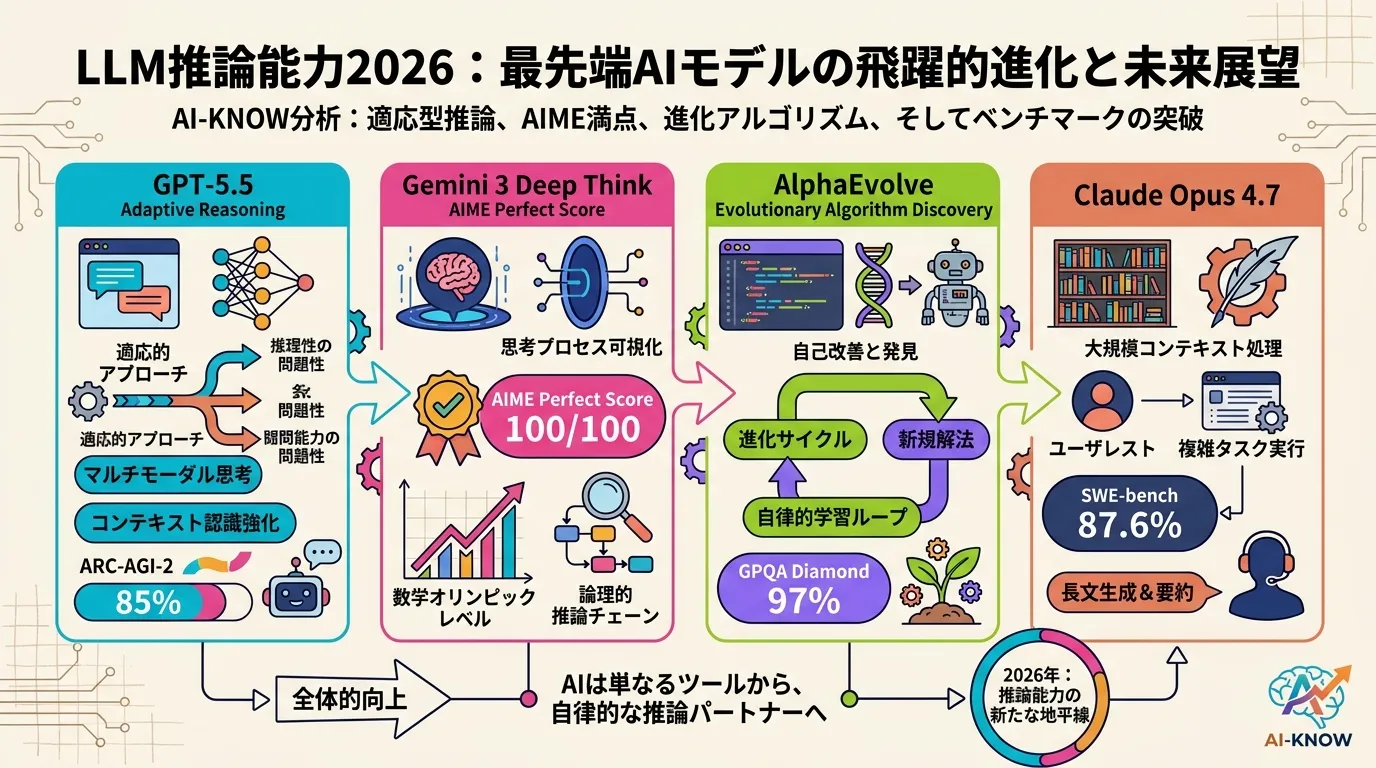
GPT-5.5(OpenAI)
GPT-5.5 は 2026 年 4 月 23 日リリース、5 月 5 日に ChatGPT のデフォルトモデルとなった。最大の特徴は「Adaptive Reasoning」——与えられた問いの難度を自動判定し、軽量な GPT-5.3 Instant と深思考モード(GPT-5.5 Thinking)を動的に切り替える機構だ。
ARC-AGI-2 では 85% でリーダーボードトップ。Terminal-Bench 2.0(エージェント的コーディング)では 82.7% で全モデル首位。さらに高リスクな医療・法律・金融プロンプトへの誤情報生成を GPT-5.3 比 52.5% 削減し、ハルシネーション問題でも前世代から大きく前進した。エージェント的な「長文脈 × 行動の連続」に強い設計で、スケールした自律 AI タスクに最適化されている。
Gemini 3 Deep Think(Google DeepMind)
Gemini 3 Deep Think は 推論モデル の中でも「科学的・数学的推論」を最大化する方向に特化した実験的フラグシップ。AIME 2023 で 99 点、IMO 2025 で金メダル相当のスコア、GPQA Diamond で 97% を記録——後者は GPT-5.4(92.8%)と Gemini 3.1 Pro(94.3%)を上回る。
2M トークンのコンテキスト窓を持ちながら深い推論ステップを展開するため、レイテンシは高い。Google Cloud 経由で研究・開発者向けに提供されており、「一問に数分かけても正解が欲しい」科学研究や定理証明といったユースケース向けだ。
AlphaEvolve(Google DeepMind)
Google DeepMind が 2026 年 5 月に発表した AlphaEvolve は、LLM が「推論して答える」のではなく「アルゴリズムを進化させて最適解を探す」コーディングエージェントだ。Gemini がコードを書き、進化的探索ループがそれを改良し続ける。
50 問の未解決数学問題のうち 75% で現行最先端を「再発見」し、20% では改善解を見出した。実運用でも Google データセンターのスケジューリング効率を平均 0.7% 向上、Gemini アーキテクチャの核心カーネルを 23% 高速化、FlashAttention の XLA 最適化で 32% 向上という実績を持つ。56 年ぶりに Strassen 行列積アルゴリズムを更新したことも話題を呼んだ。
Claude Opus 4.7(Anthropic)
Claude Opus 4.7 は抽象推論(ARC-AGI-2)と多ファイルコード推論で強みを発揮。ARC-AGI-2 は Claude Opus 4.6 の 68.8%(2026 年 2 月時点)から前世代比で大幅進化し、SWE-bench Verified では 87.6% でコード推論のトップに立つ。複雑な指示を長文脈で一貫追跡する設計が際立つ。
比較表:推論能力 4 軸で整理
| モデル | GPQA Diamond | ARC-AGI-2 | SWE-bench Verified | アプローチ |
|---|---|---|---|---|
| GPT-5.5 | — | 85.0% | 82.7% | Adaptive Reasoning |
| Gemini 3 Deep Think | 97.0% | — | — | 深思考特化 |
| Claude Opus 4.7 | — | 68.8%* | 87.6% | 長文脈推論 |
| GPT-5.4 Pro | 92.8% | 83.3% | — | — |
| Gemini 3.1 Pro | 94.3% | 77.1% | — | — |
*Claude Opus 4.6(2026年2月)。Opus 4.7 は未公表スコア。
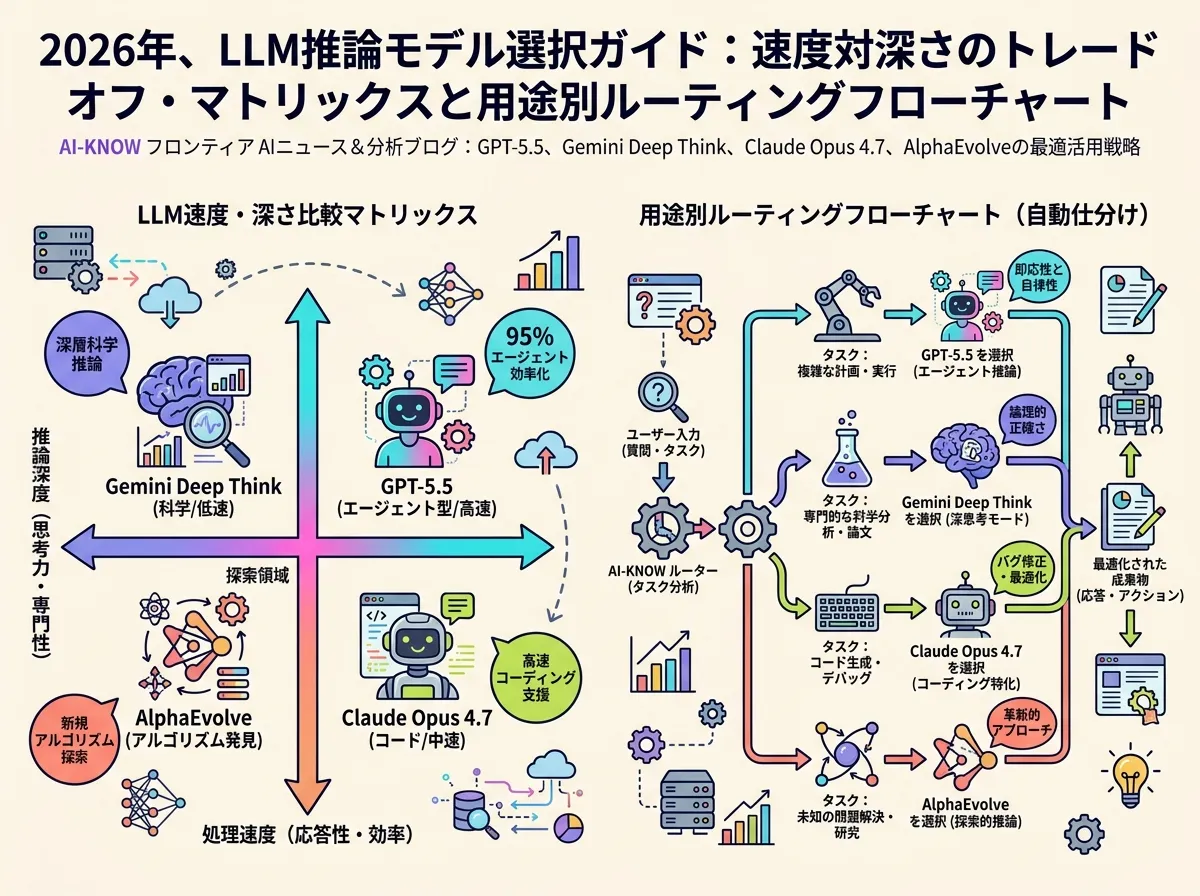
使い分けの推奨
数学・科学的定理証明・研究補助では Gemini 3 Deep Think が第一選択。IMO 金メダル・AIME 99 点という実績が示す通り、精密な段階推論の精度は他モデルの追随を許さない。時間コストを許容できる研究者・科学エンジニアに向く。
エージェント的コーディング・長期タスク実行では GPT-5.5 が最適。ARC-AGI-2 85% と Terminal-Bench 82.7% の組み合わせは「新しい問題構造を認識しながら複数ステップにわたってツールを使う」自律タスクに直結する。ハルシネーション半減の恩恵も大きい。
大規模コードベースへの継続的理解・多ファイル作業では Claude Opus 4.7 の 87.6% SWE-bench Verified が光る。長文脈での指示追跡と一貫した修正判断が求められるソフトウェア開発支援に最適だ。
アルゴリズム最適化・数学的未踏領域の探索では AlphaEvolve が別格。「答えを出す」モデルではなく「アルゴリズムを改良し続けるエージェント」という設計思想は他とカテゴリが違う。Google Cloud での提供が今後拡大予定だ。
2026 年の見通し
推論能力の競争軸は 3 方向に向かっている。
テストタイムスケーリングの深化: 推論モデルに与える計算量(テスト時コンピュート)を増やすほど精度が上がるという「推論スケーリング則」の適用が加速する。Process Reward Model(中間ステップへのフィードバック)と Reflective Agent(自己修正ループ)の組み合わせが標準になりつつある。
潜在推論(Latent Reasoning): Latent-GRPO など、トークン列ではなく埋め込み空間で推論を行うアプローチが 2026 年に複数登場した。DeepLatent Reasoning は 思考の連鎖 の中間ステップへのハルシネーションを 27% から 9% に削減。トークン生成コストを省きながら推論精度を上げる次世代手法として注目される。
戦略的推論の限界: しかし推論能力の向上は万能ではない。不完全情報ゲームにおける研究(arxiv: 2605.00226)は、最先端モデルでも内部信念・言語報告・行動選択の三重解離が生じ、合成的複雑度の高い状況では 90% 超の精度が 20% 台に崩落することを示した。「推論できる」ことと「戦略的に行動できる」ことの間には依然として大きな溝がある。
参考:GPT-5.5 発表(OpenAI, 2026)、GPT-5.5 Instant(OpenAI, 2026)、AlphaEvolve: Gemini-powered coding agent(Google DeepMind, 2026)、AlphaEvolve Impact(Google DeepMind, 2026)、Gemini Deep Think: Advancing scientific discovery(Google DeepMind, 2026)、ARC-AGI-2 Technical Report(ARC Prize, 2026)、Why Do LLMs Struggle in Strategic Play?(arxiv
.00226, 2026)、Latent-GRPO: Group Relative Policy Optimization for Latent Reasoning(arxiv.27998, 2026)、AI Trends 2026: Test-Time Reasoning(HuggingFace Blog, 2026)、GPT-5 vs Gemini 2026 Full Benchmark(BenchLM.ai, 2026)関連記事

AI 評価インフラの現在地 2026 — MMLU 飽和から HAL・SWE-bench Pro・HLE まで、ベンチマーク選択の実践ガイド
AI 計算インフラ投資の現在地 2026 — Anthropic 500 億ドル / xAI Colossus / Google-Broadcom を比較する
AI の現在地を読む 10 枚のグラフ — Stanford AI Index 2026 × MIT TR が照らす進化と格差
宇宙 AI インフラ 2026 — Google・SpaceX・Cowboy Space・Blue Origin の軌道上計算レース比較
エッジ向けオムニモデルの現在地 2026 — Gemma 3n / Nemotron Nano Omni / Granite 4.1 を用途別に比較する