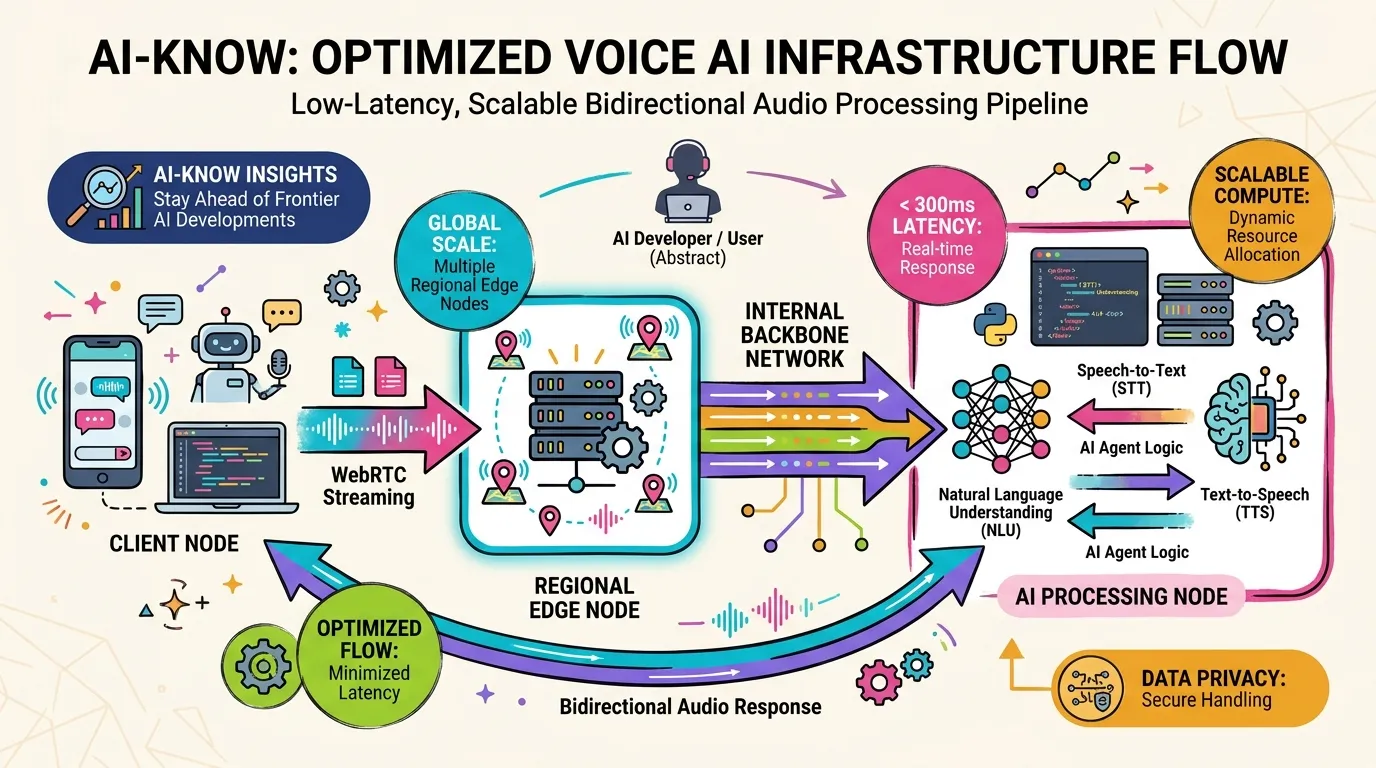
Real-Time LLM
Real-Time LLM refers to LLM infrastructure and system design capable of delivering inference and responses at the low latencies required for natural human conversation — typically under 300ms end-to-end. Unlike standard batch-processing LLM inference, real-time systems require streaming token generation, support for interactive interruption, and integration with turn-taking detection.
OpenAI’s Realtime API established the reference implementation, combining streaming token generation with audio output synthesis to minimize end-to-end latency. Real-Time LLM is the primary infrastructure component setting the quality ceiling for Voice AI products, and tight integration with WebRTC Stack architecture is essential.
Key design metrics extend beyond raw inference speed to include robustness under low-bandwidth conditions and session stability for extended conversations.