How OpenAI Rebuilt Its WebRTC Stack from Scratch to Deliver Low-Latency Voice AI at Scale
Inside the infrastructure powering Realtime API — and why off-the-shelf WebRTC libraries could not meet the bar
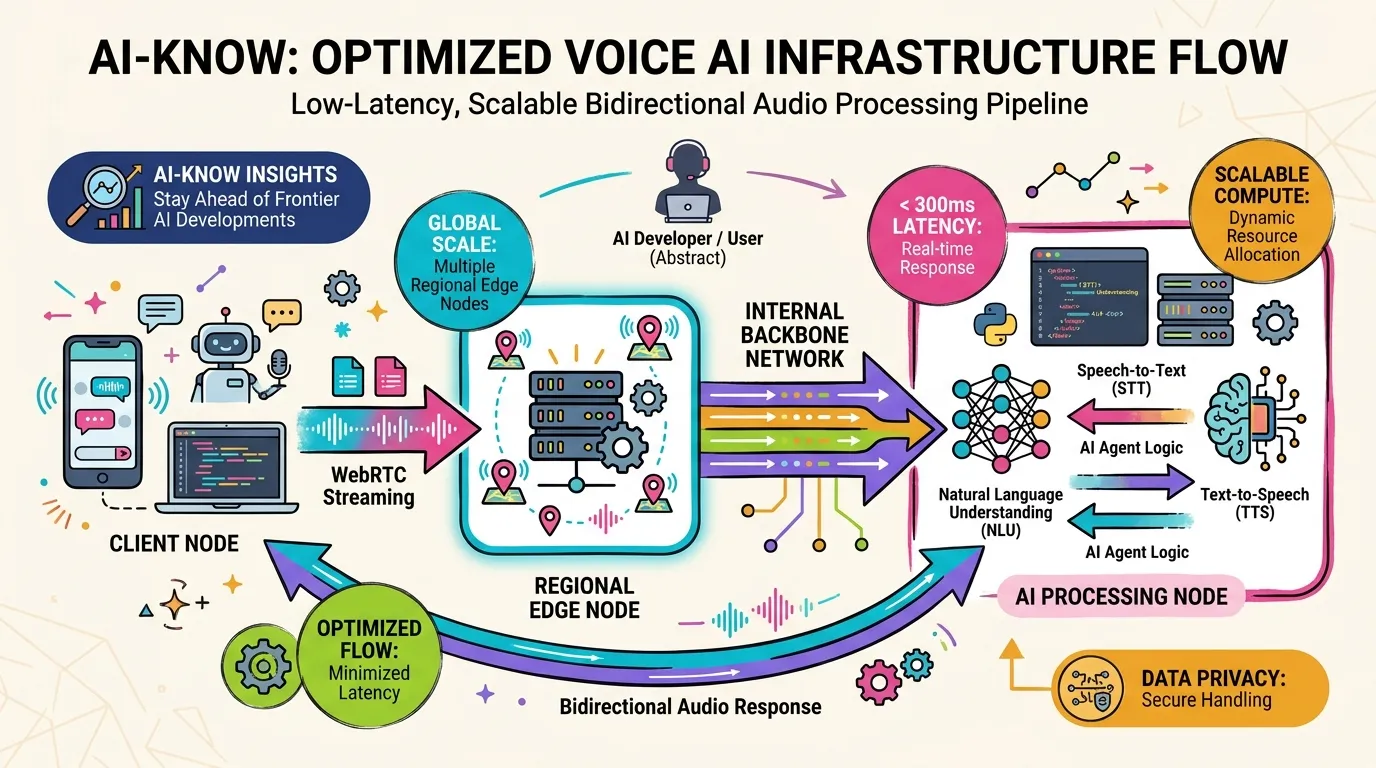
As large language models commoditize across text and image, Voice AI is emerging as the next competitive frontier. OpenAI recently published an engineering blog post explaining how it delivers its Realtime API at global scale — and the headline reveal is that it rebuilt its WebRTC Stack from scratch. Working from the public summary, here is what that decision tells us about where voice AI infrastructure is headed.
Why WebRTC at All
WebRTC (Web Real-Time Communication) is the open standard powering real-time audio and video in browsers. It handles signaling, media transport, and codec negotiation, and has long been the backbone of video conferencing and VoIP tools.
OpenAI’s choice of WebRTC as the foundation for Realtime API makes sense: it is native to browsers and mobile platforms, requiring no SDK install on the client side. For a product that needs to be embedded into every kind of app, minimizing integration friction matters enormously. Because WebRTC was designed for bidirectional audio streaming from the ground up, it fits naturally with the demands of Real-Time LLM inference.
Why Off-the-Shelf Wasn’t Enough
The more significant signal is that OpenAI rebuilt the stack from scratch — implying existing WebRTC libraries hit a ceiling. The likely reasons:
1. Latency optimization at a global scale
Achieving sub-300ms end-to-end latency across regions requires tuning signal paths, edge node placement, and buffering strategies that generic libraries cannot expose. Off-the-shelf solutions optimize for the common case; OpenAI needs optimization for their case.
2. Massive concurrent session handling
Deploying voice AI across ChatGPT’s user base means handling potentially millions of concurrent sessions at peak. Generic WebRTC libraries are not typically designed to the operational requirements of that scale.
3. Tight coupling with the AI model pipeline
In a voice AI system, every layer of the WebRTC Stack — codec selection, jitter buffering, packet loss recovery — creates tradeoffs that affect the audio quality going into and out of the model. Owning the stack lets OpenAI tune those tradeoffs against its own speech model’s input requirements and output latency characteristics.
Inferred Architecture
Based on the public description, the architecture likely follows this pattern:
Client (Browser / Mobile App)
↓ WebRTC (SRTP / DTLS)
Regional Edge Node (nearest region)
↓ Internal low-latency backbone
AI Processing Node (STT → LLM → TTS)
↓ WebRTC
ClientEdge nodes in each region minimize the public internet hop from user to system. Internal backbone connections — dedicated fiber or low-latency VPC peering — remove public internet variability from the most critical path: the round-trip between the edge and the AI model.
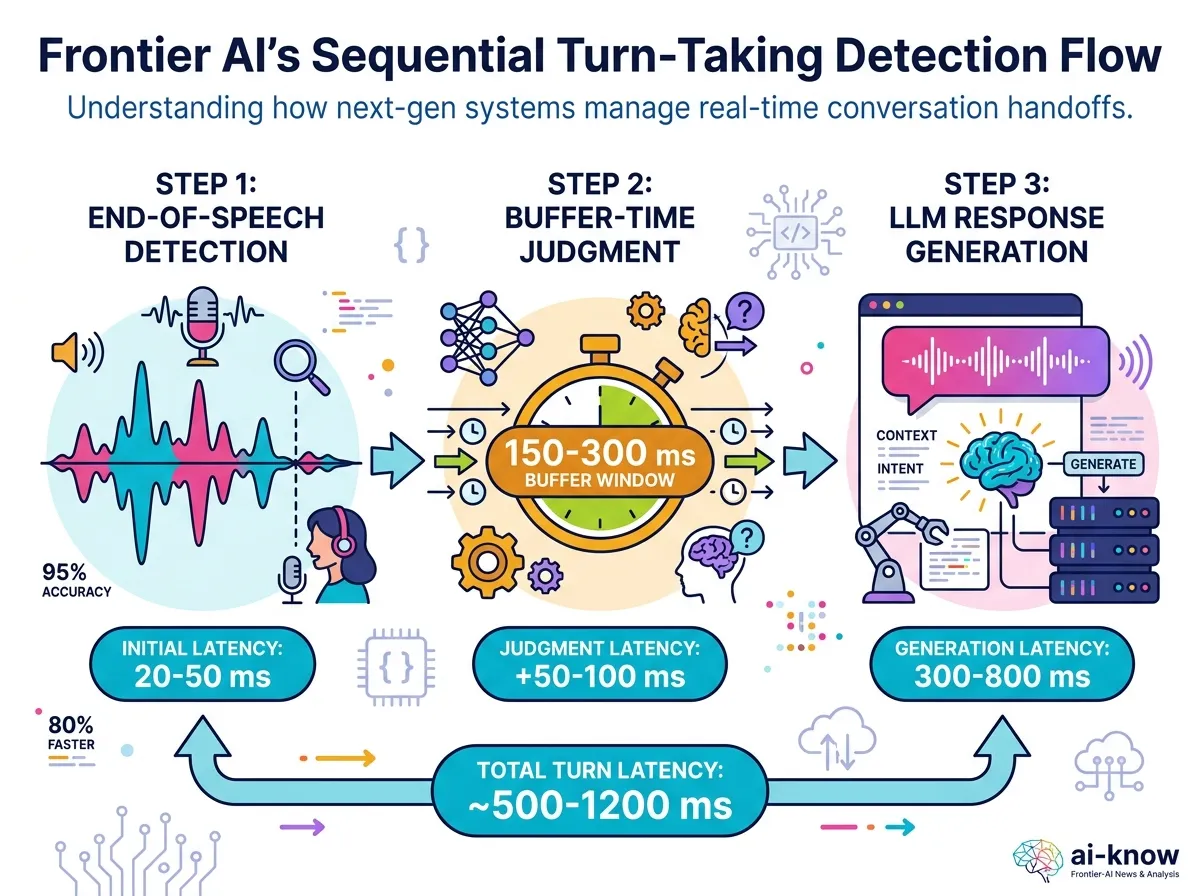
The Hard Problem: Turn-Taking
One of the technically deepest challenges in Voice AI is natural turn-taking — detecting when a speaker has finished rather than paused. Humans do this effortlessly using acoustic cues (silence duration, pitch contour, volume dynamics) combined with conversational context. AI systems must replicate this in real time.
Too slow to detect end-of-turn and the AI seems unresponsive. Too eager and it interrupts mid-sentence. Getting this balance right is increasingly the key differentiator for Real-Time LLM products.
The Competitive Landscape
OpenAI’s infrastructure investment signals that voice AI has crossed from “LLM add-on” to “independent product category.” xAI Grok Voice, Google Gemini Live, and Apple Intelligence’s voice layer are all in motion simultaneously. The quality ceiling for voice AI is now set by infrastructure depth.
A competitor running on commodity WebRTC libraries and a competitor with a purpose-built stack will diverge in optimization velocity over the next two to three years. OpenAI’s choice to rebuild from scratch is a heavy upfront investment — but it also means they retain full control over the variables that determine voice quality, latency, and scale.
Bottom Line
Rebuilding a WebRTC stack looks unglamorous from the outside. But if the goal is to simultaneously achieve sub-300ms latency, natural turn-taking, and broadcast-scale concurrent sessions, off-the-shelf tooling hits a wall. OpenAI’s decision to build its own WebRTC Stack is an architectural commitment: voice AI is not an experiment, it is a product category that deserves its own infrastructure.
Sources: How OpenAI delivers low-latency voice AI at scale (OpenAI News, 2026)
Related Articles
The Year AI Agents Reshape Enterprise Systems — MCP Becomes the Connectivity Standard
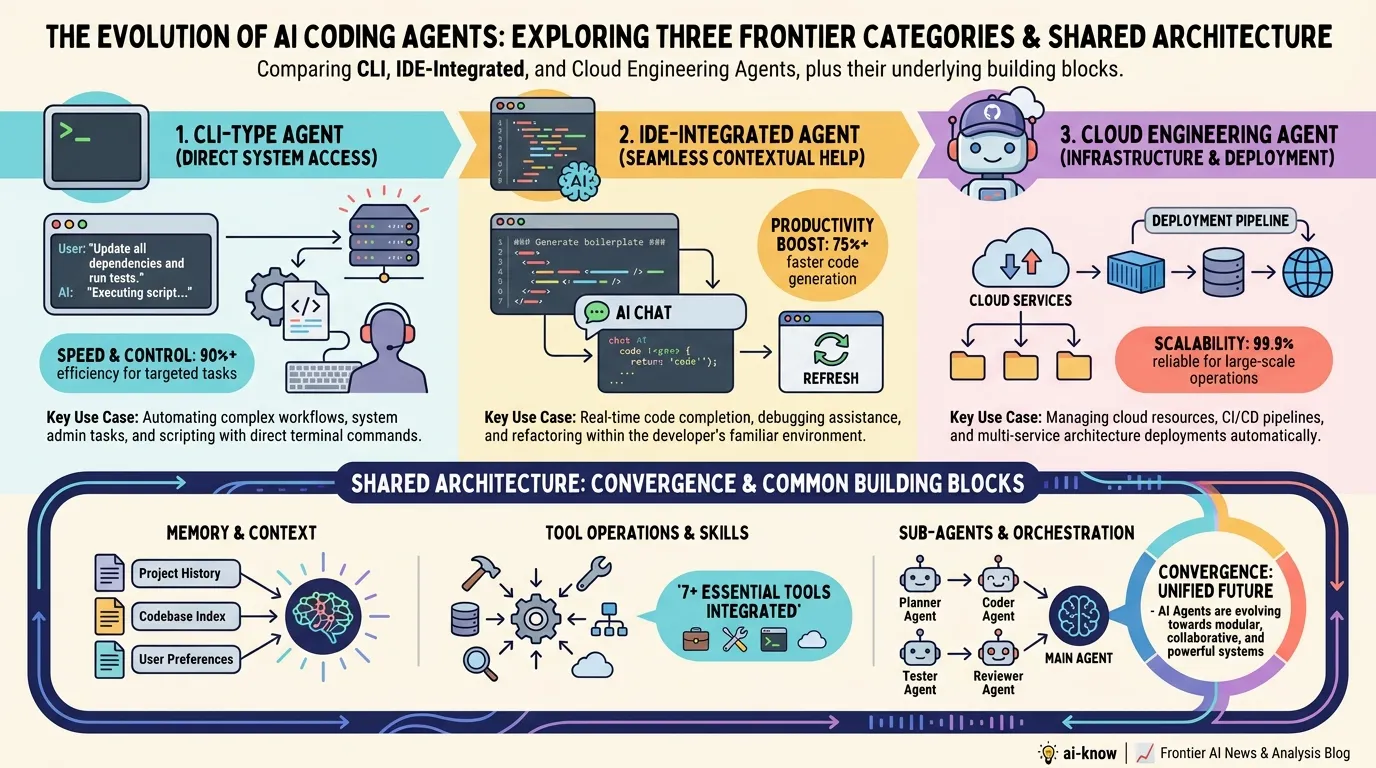
The State of AI Coding Agents in 2026: Architectural Convergence and the Context Engineering Era
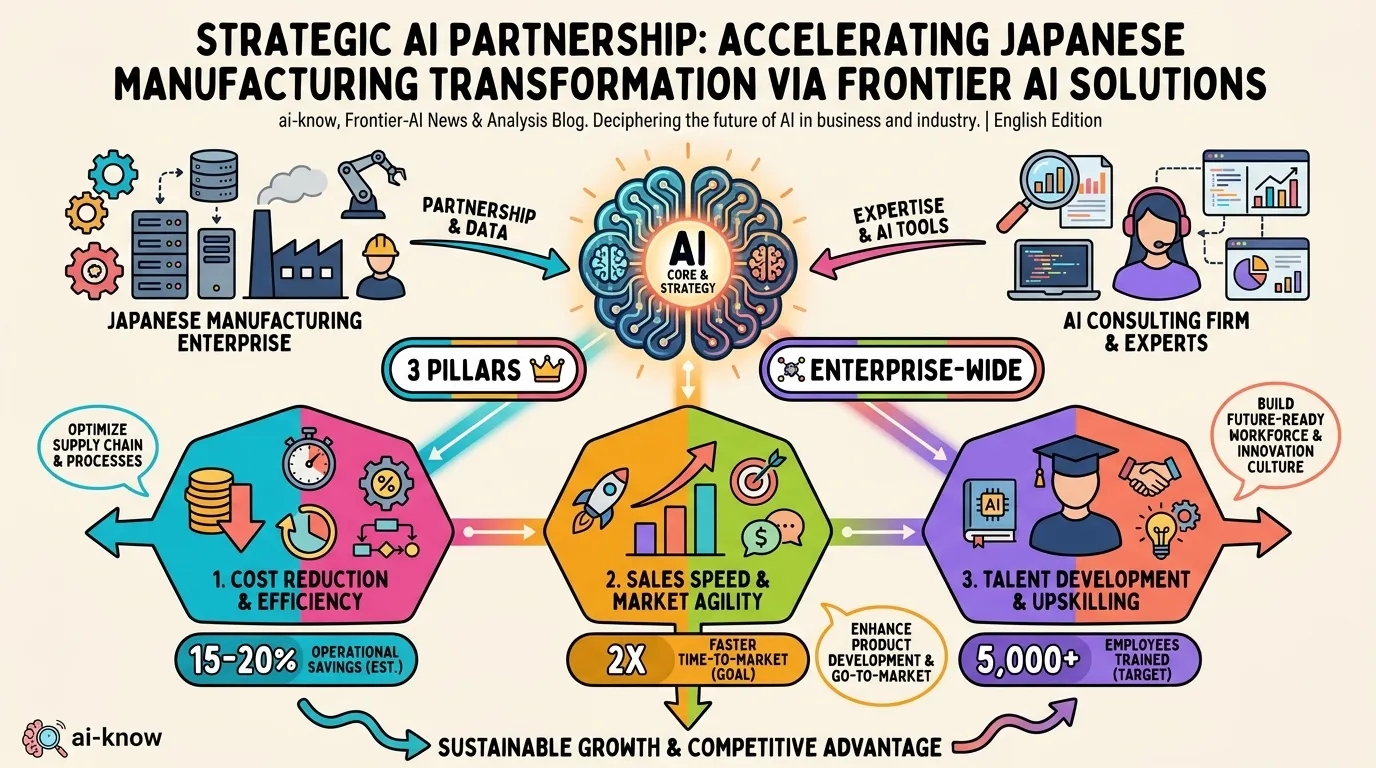
Accenture × NSK: AI-Driven Business Reinvention Moves to Full Scale in Japanese Manufacturing