OpenAI が公開する Codex の4層防衛 — エージェント「暴走防止」の設計思想
サンドボックス・承認フロー・ネットワーク allowlist・エージェントネイティブテレメトリで構成される制御プレーンが、自律コーディングエージェントを安全な「workforce」に変える
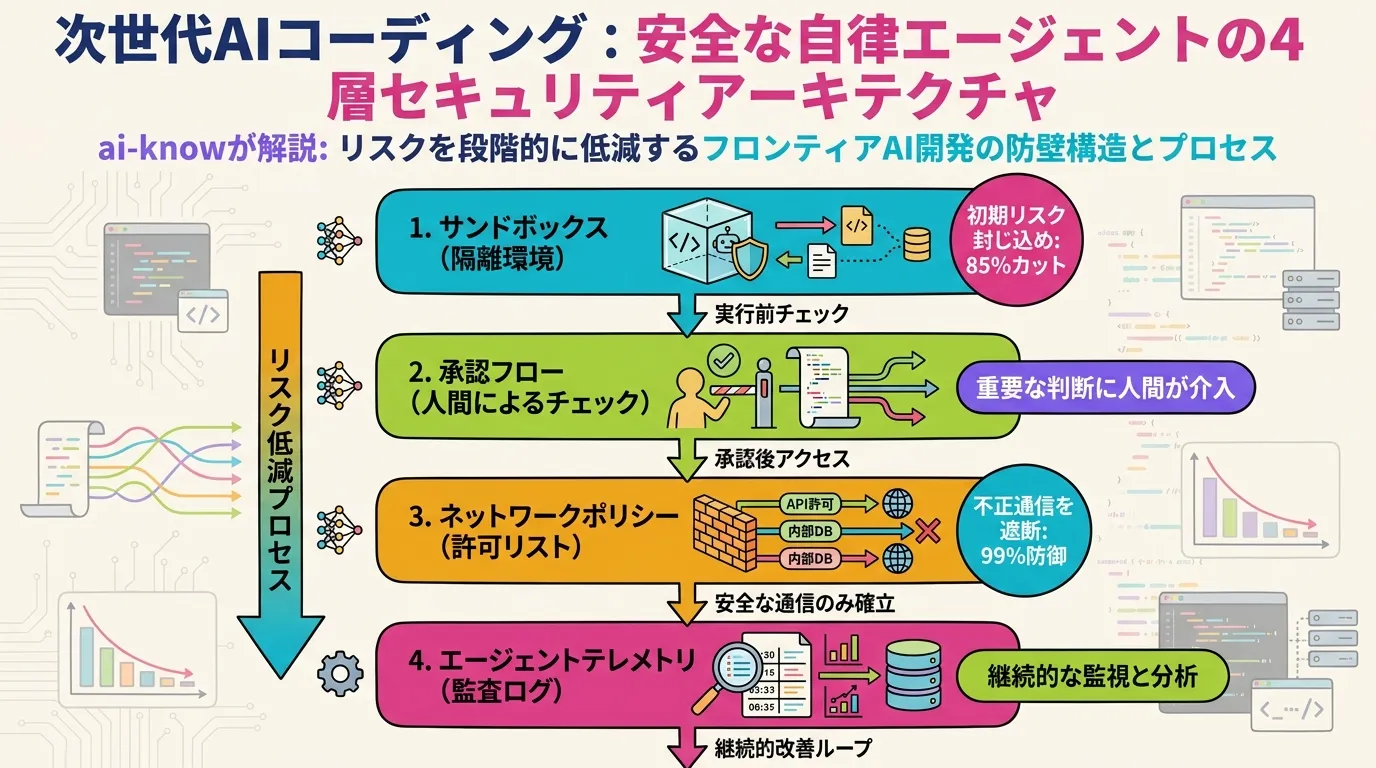
コーディングエージェントは「補助ツール」から「組織内で自律的に動く workforce」へと格上げされた。しかし、その強力さは諸刃の剣でもある。エージェントは予測不能なコマンド列を生成し、ファイルを書き換え、外部 API を叩き、場合によっては本番環境にデプロイまで試みる。この「破壊力」をどう制御するか、OpenAI が自社内で AI コーディングエージェント の Codex を安全に運用するために構築した4層の防御アーキテクチャを公開した。
Cloudflare が AI 自動化により 1,100 名を削減したと報じられた同日(2026年5月8日)の発表は、業界に対して明確なメッセージを送っている。「エージェントを安全に動かすノウハウがあれば、大規模展開のハードルを下げられる」という宣言だ。
第1層:サンドボックス — 実行環境を隔離する
サンドボックス は エージェント型 AI 安全運用の基盤をなす。Codex の実装では、コード実行・ファイル操作・プロセス起動をすべてホスト環境から切り離された隔離コンテナ内で完結させる。
重要なのは「filesystem / network / process の全レイヤでの隔離」であること。エージェントがランダムなシェルコマンドを実行しても、その影響範囲はサンドボックス内に留まる。コンテナ外の本番 DB や認証情報は原則として見えない設計になっている。
「サンドボックスなしのコーディングエージェントは、管理者権限で動く AI にルートアクセスを渡すようなもの」
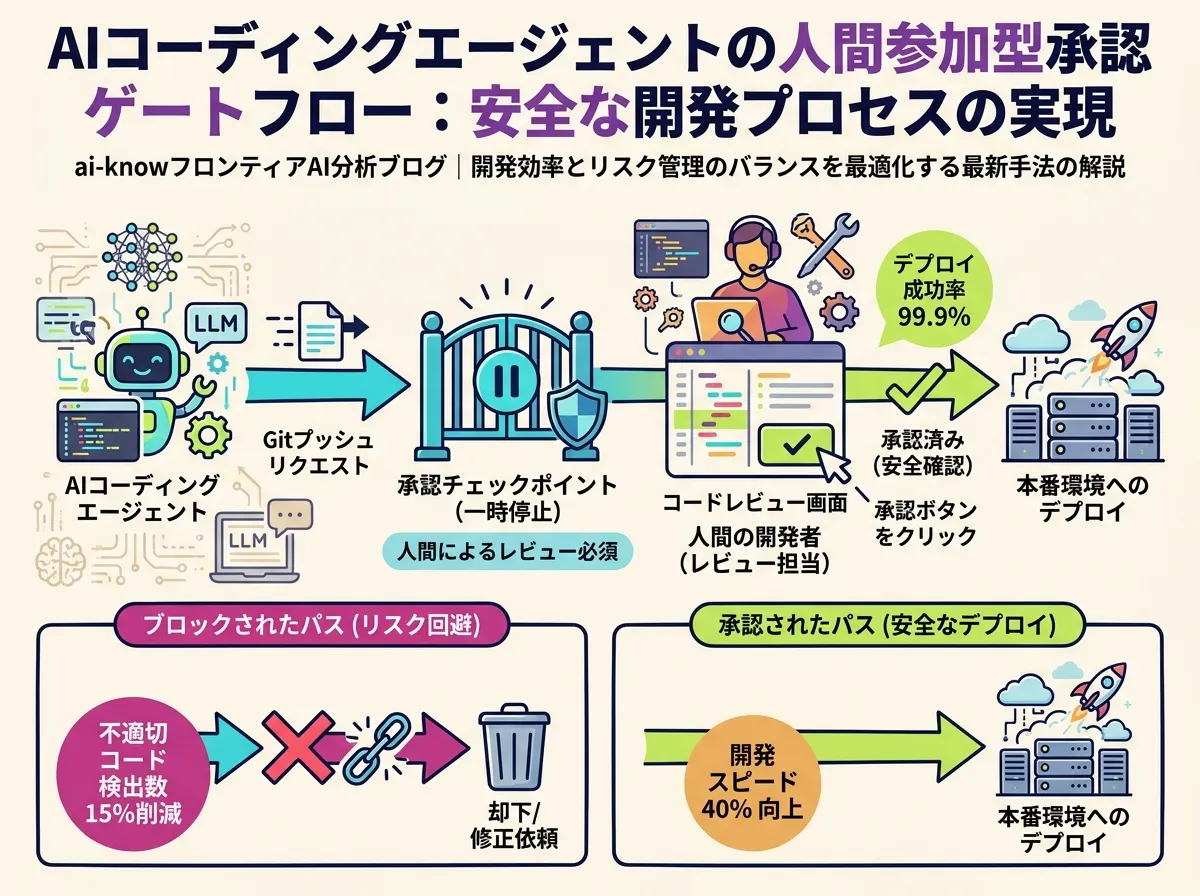
第2層:承認フロー — リスク操作を人間が止める
Human-in-the-Loop (HITL) 設計は、AI 安全性 の文脈で広く語られるが、Codex では具体的にどの操作が「承認必須」になるかが定義されている。git push(本番ブランチへ)・本番環境への書き込み・外部サービスへの認証付きリクエストといった「後から戻せない操作」がそのトリガーだ。
エージェントはこれらの操作を実行しようとする前に自動的に停止し、人間がレビュー・承認するまで待機する。完全自律ではなく「重要なジャンクションでは必ず人間が関与する」設計が、大規模組織でのエージェント展開を現実的にする。
第3層:ネットワークポリシー — 外向き通信を allowlist 制御
コーディングエージェントが「外部と通信する」という事実は、従来のセキュリティモデルで想定されていなかった問題を引き起こす。NPM パッケージのインストール・GitHub API 呼び出し・LLM API へのリクエストなど、必要な通信は多いが、それ以外をすべてブロックすることが重要だ。
Codex では 明示的な allowlist を設け、許可された宛先以外への通信はネットワークレベルで遮断する。エージェントがサプライチェーン攻撃のペイロードを誤ってダウンロードしようとしても、allowlist 外の通信はドロップされる。
第4層:エージェントネイティブテレメトリ — APM では捉えられない観測
従来の Application Performance Monitoring(APM)はリクエスト・レイテンシ・エラーレートを追跡するが、エージェントが「なぜそのコマンドを実行したか」という推論ステップまでは観測できない。
エージェントテレメトリ はこのギャップを埋める。ツール呼び出しのシーケンス・サブエージェントへの遷移・ファイル変更の因果関係を構造化ログとして収集し、事後に「エージェントが何をしたか」を完全に再現・監査できるようにする。インシデント発生時の根本原因分析と、エージェント挙動の継続的な改善の両方に機能する。
業界トレンド:安全なエージェント展開の競争
OpenAI のこの公開は、Anthropic が5月5日に Claude Security ベータを発表したわずか数日後に行われた。両社のアプローチは異なる視点を持つ。Anthropic は「エージェントを受け入れる側の組織が、どう Claude の権限を制御するか」を扱うのに対し、OpenAI は「エージェントを提供・運用する側が、どう内部統制を組むか」を示している。
「使う側」と「作る側」の両面で AI 安全性 の実装知見が公開され始めていることは、2026年がエージェント普及の本番フェーズに入ったことを示すシグナルだ。
まとめ
Codex の4層防衛は「エージェント workforce を安全に機能させるための制御プレーン」の実装例として、業界標準に近い設計指針を示している。サンドボックス・承認フロー・ネットワーク allowlist・エージェントネイティブテレメトリのいずれを欠いても、「自律性」は「無制御なリスク」に変わる。
組織が AI コーディングエージェント を導入する際には、この4層を参照点にセキュリティ設計を評価するのが当面のベストプラクティスになるだろう。
関連記事
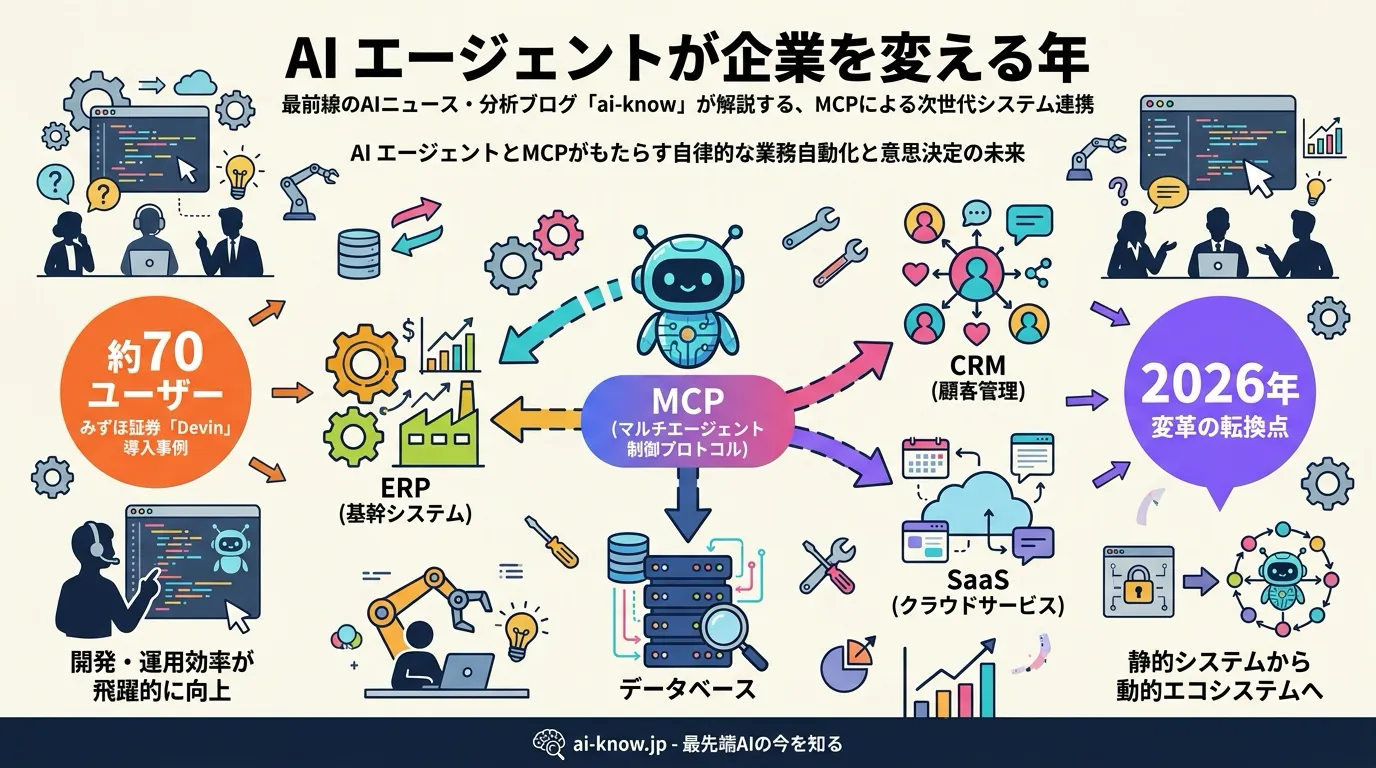
AI エージェントが企業システムを変える年 — MCP が接続標準を握る
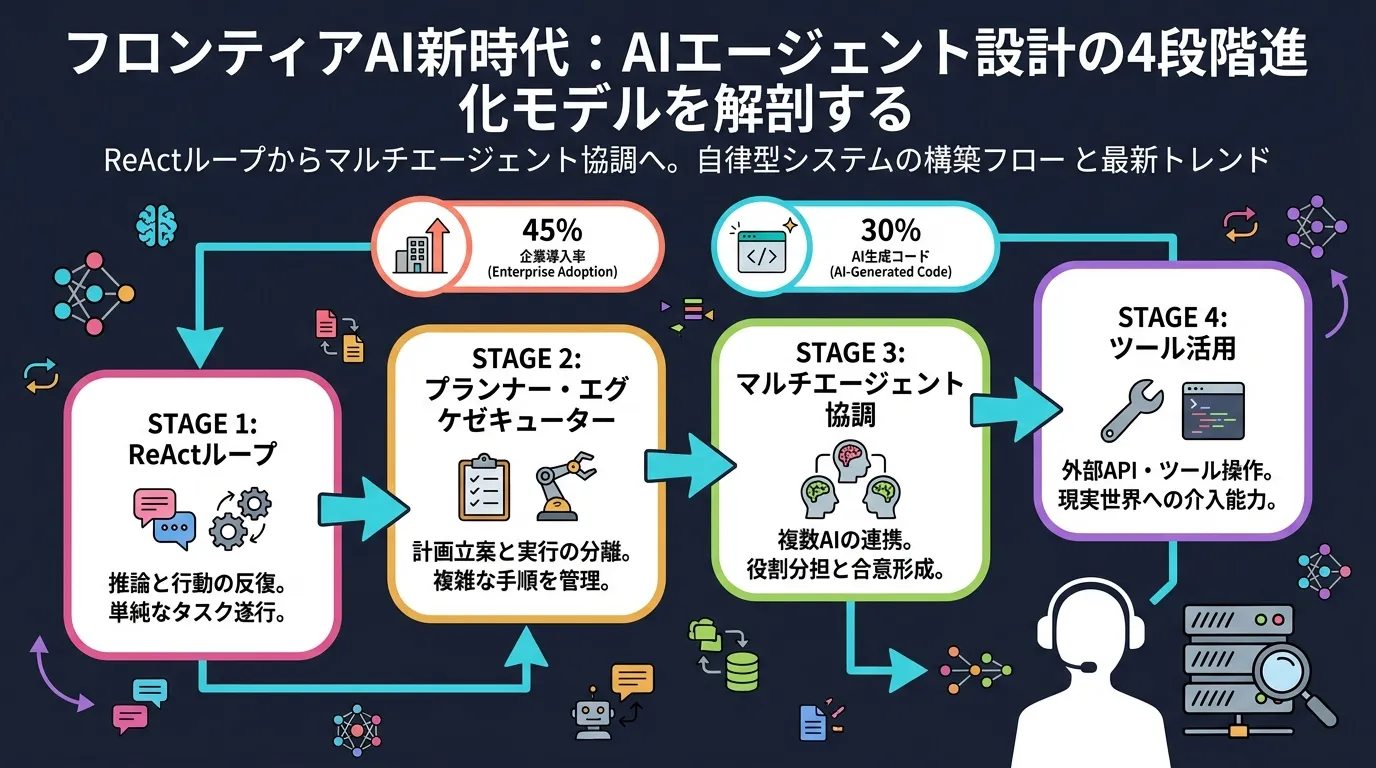
AIエージェント設計 2026:ReActループ・MCP・マルチエージェントで押さえる 4 つの実践パターン
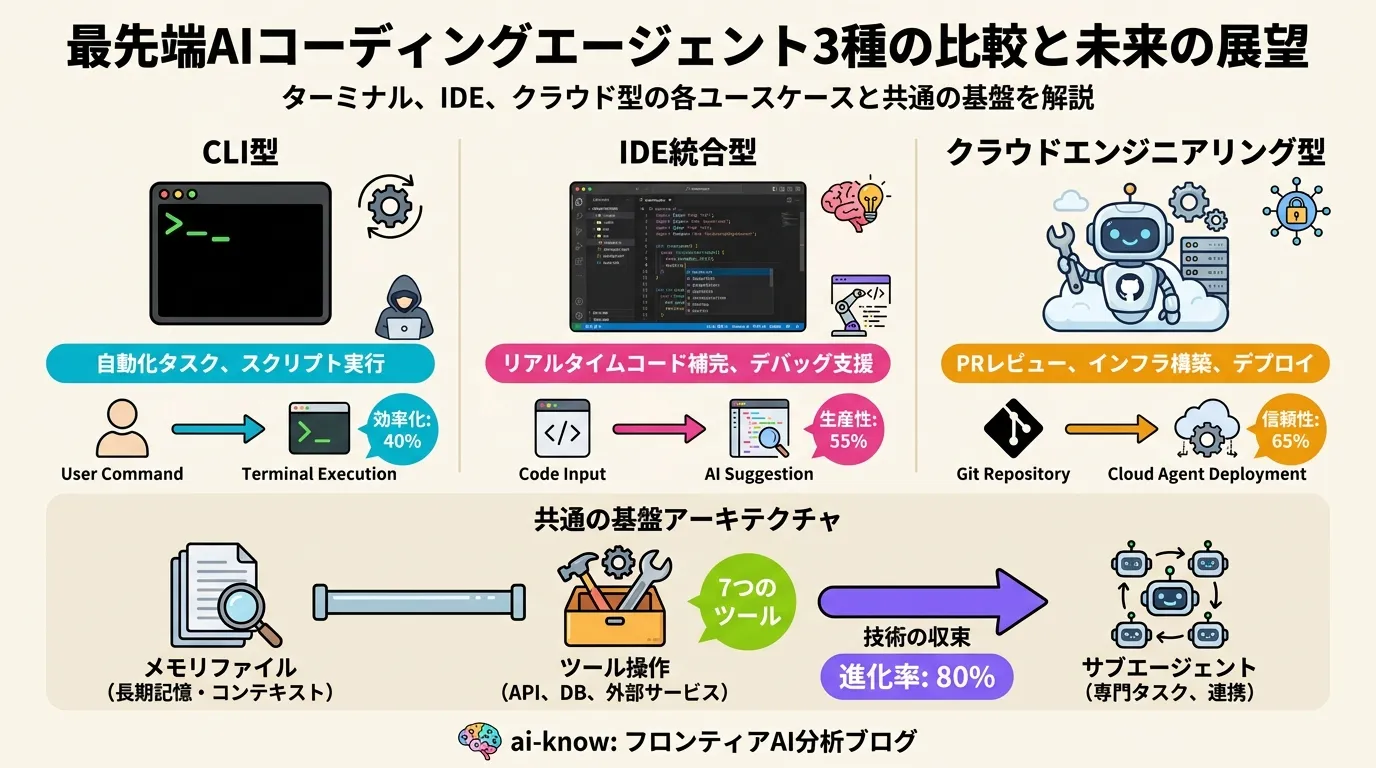
AI コーディングエージェント 2026:ペアプロからチーム自律化へ、アーキテクチャ収束の全貌
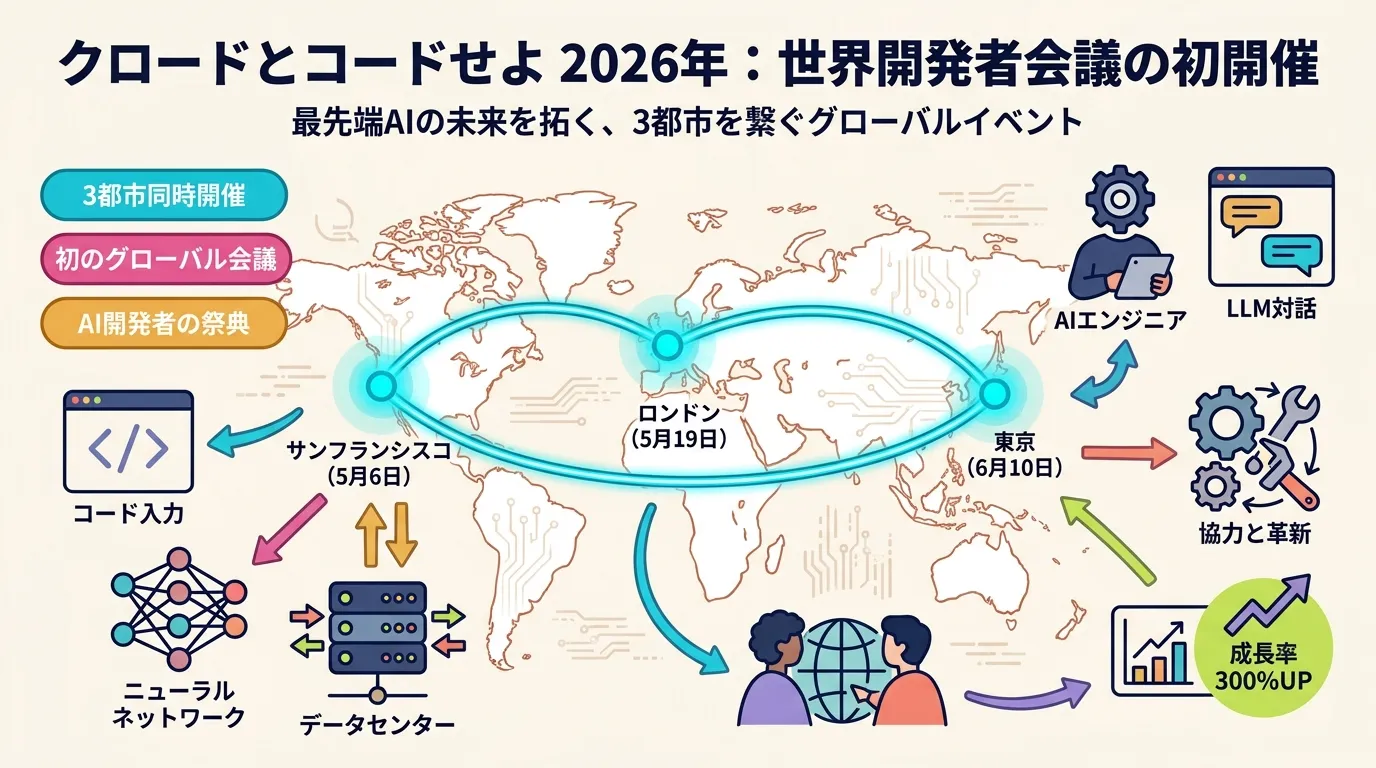
Anthropic「Code w/ Claude 2026」開幕 — 自律型 AI コーディングの次章が SF から始まる
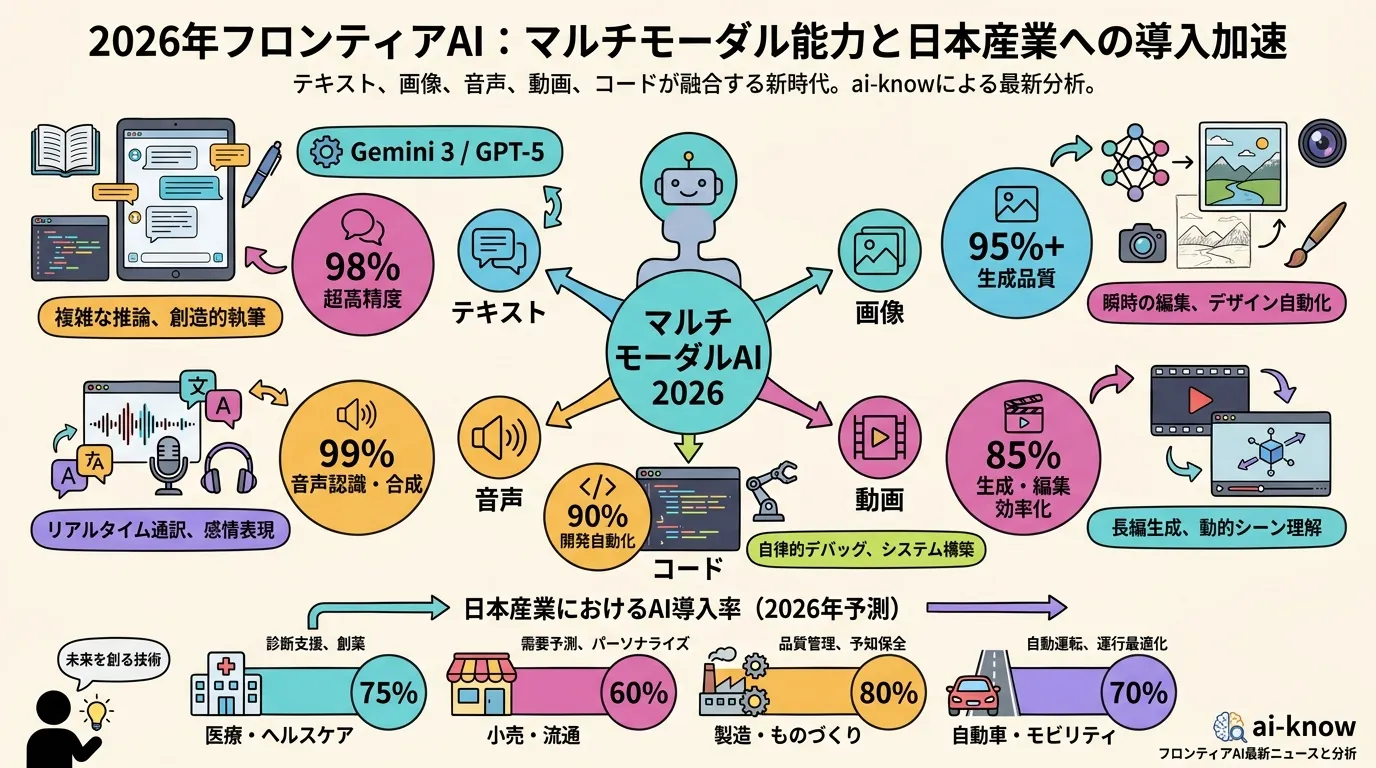
マルチモーダル LLM は「必須インフラ」へ — 2026 年の国内採用動向と native multimodal 設計の台頭