OpenAI's Four-Layer Defense for Codex — Engineering Safe Agentic Code Execution
Sandboxing, human-in-the-loop approvals, network allowlists, and agent-native telemetry form the control plane that turns autonomous coding agents into trustworthy workforce
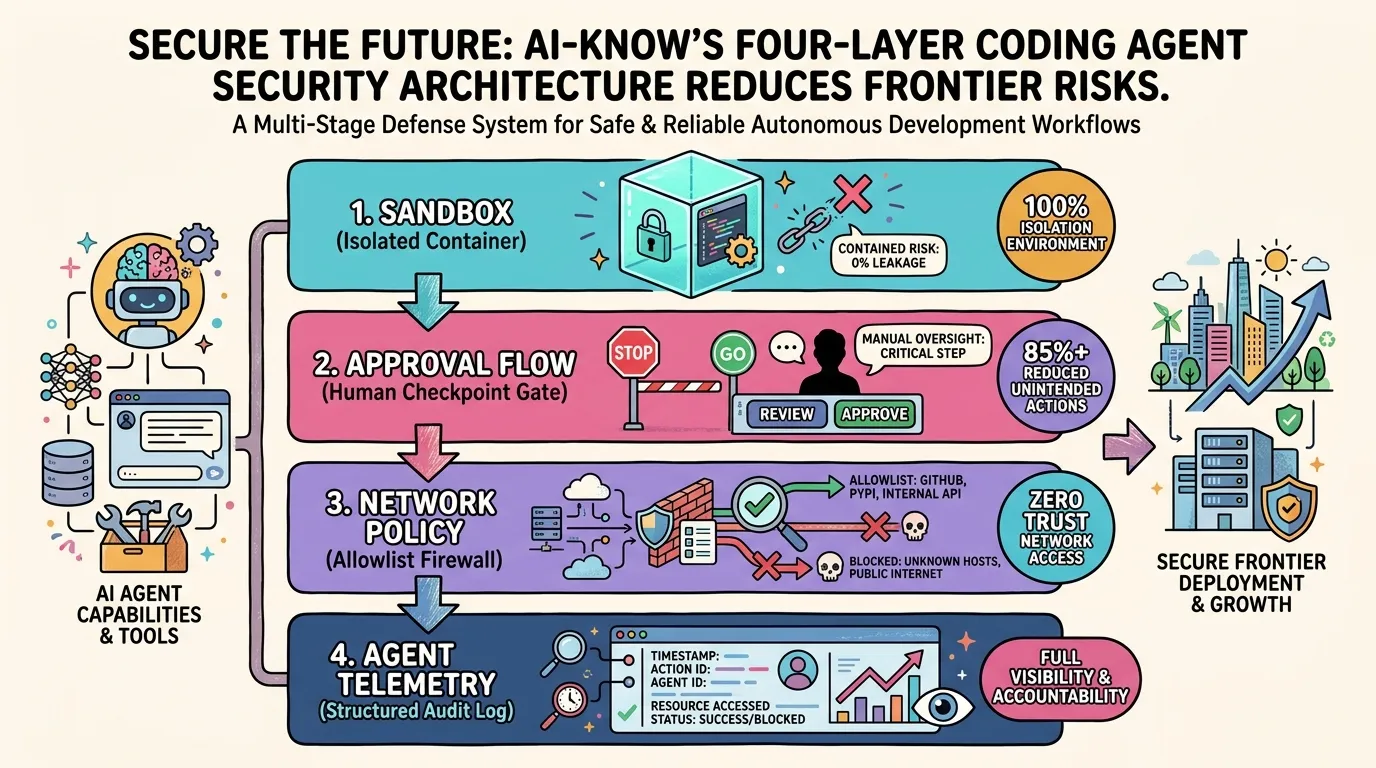
Coding agents have graduated from “assistant tools” to “autonomous workforce operating inside organizations.” That power cuts both ways. An agent can generate unpredictable command sequences, overwrite files, call external APIs, and — left unchecked — attempt to deploy to production. OpenAI has now publicly documented the four-layer defense it built to run Codex safely in-house, offering the industry a concrete blueprint for deploying AI Coding Agents at scale.
The announcement landed on May 8, 2026 — the same day Cloudflare disclosed eliminating 1,100 roles through AI automation. The timing is no accident: demonstrating a rigorous safety posture lowers the organizational barrier for adopting agentic coding at scale.
Layer 1: Sandboxing — Isolating the Execution Environment
Sandboxing is the foundation of safe Agentic AI operations. Codex runs all code execution, file operations, and process spawning inside isolated containers that are fully separated from the host environment.
The key property is multi-layer isolation across filesystem, network, and process namespaces. An agent can execute arbitrary shell commands within its sandbox without affecting production databases, credentials, or any resource outside the container boundary. Blast radius is contained by design.
“A coding agent without a sandbox is handing root access to an AI running under admin privileges.”
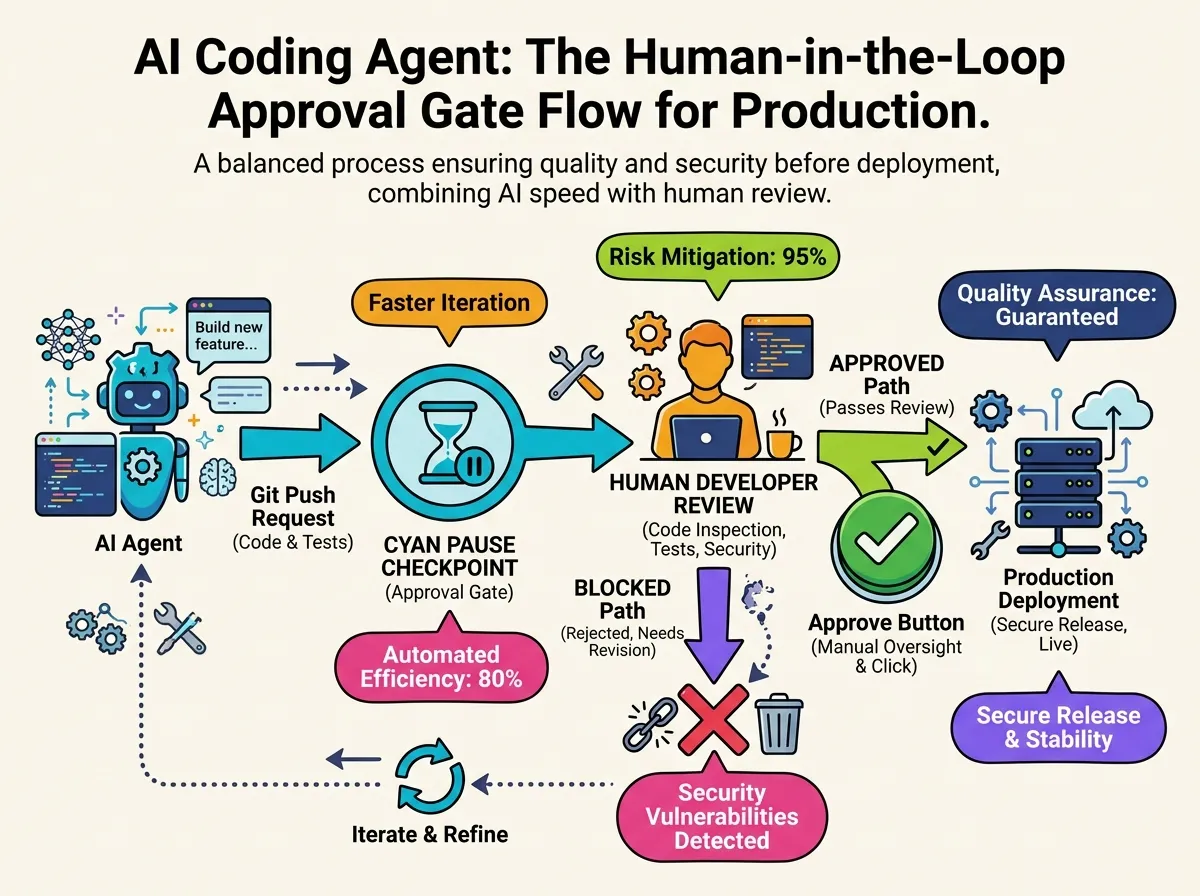
Layer 2: Approval Flows — Humans at the Critical Junctions
Human-in-the-Loop (HITL) design appears throughout AI Safety literature, but Codex pins it to specific trigger operations: pushing to production branches via git push, writing to production environments, and issuing authenticated requests to external services — in short, any action that is hard or impossible to reverse.
When Codex reaches one of these gates, it stops automatically and waits for a human to review and approve before proceeding. The model is not full autonomy but “autonomy with mandatory human checkpoints at high-stakes junctions” — a posture that makes large-scale organizational deployment realistic.
Layer 3: Network Policy — Allowlist-Controlled Outbound Traffic
A coding agent that communicates with the outside world introduces attack surfaces that traditional security models were never designed for. Installing npm packages, calling GitHub APIs, or reaching LLM inference endpoints are all necessary, but everything else should be blocked.
Codex implements an explicit allowlist: outbound traffic to non-approved destinations is dropped at the network layer. Even if an agent attempts to download a malicious supply-chain payload, the request never leaves the sandbox’s authorized perimeter.
Layer 4: Agent-Native Telemetry — Observability Beyond APM
Conventional Application Performance Monitoring tracks request rates, latency, and error counts — none of which captures why an agent issued a particular command sequence. Agent Telemetry fills that gap.
Tool-call sequences, sub-agent transitions, and file-change causality are collected as structured logs that make it possible to fully replay what an agent did after the fact. This enables both post-incident root-cause analysis and continuous improvement of agent behavior — neither of which is possible with traditional APM alone.
Industry Context: The Race to Safe Agent Deployment
OpenAI’s publication came just days after Anthropic launched Claude Security beta on May 5. The two approaches are complementary. Anthropic focuses on giving receiving organizations fine-grained control over Claude’s permissions and surface area. OpenAI documents how the provider and operator builds internal controls to govern its own agent fleet.
Both perspectives of AI Safety implementation becoming public simultaneously signals that 2026 is the year agentic AI moves from early adoption into production-scale deployment.
Takeaway
Codex’s four-layer defense is the clearest industry reference design yet for the control plane required to operate an agent workforce safely. Remove any of the four layers — sandboxing, approval flows, network policy, or agent-native telemetry — and “autonomy” becomes “uncontrolled risk.”
Organizations evaluating AI Coding Agents adoption should treat these four layers as the baseline security checklist for their deployment design.
Related Articles
The Year AI Agents Reshape Enterprise Systems — MCP Becomes the Connectivity Standard
AI Agent Architecture in 2026: Four Essential Design Patterns for Production
The State of AI Coding Agents in 2026: Architectural Convergence and the Context Engineering Era
Anthropic Launches "Code w/ Claude 2026" — The Next Chapter of Agentic Coding Begins in SF
Multimodal LLMs Become Essential Infrastructure: Japan Adoption Trends and the Native Multimodal Shift in 2026