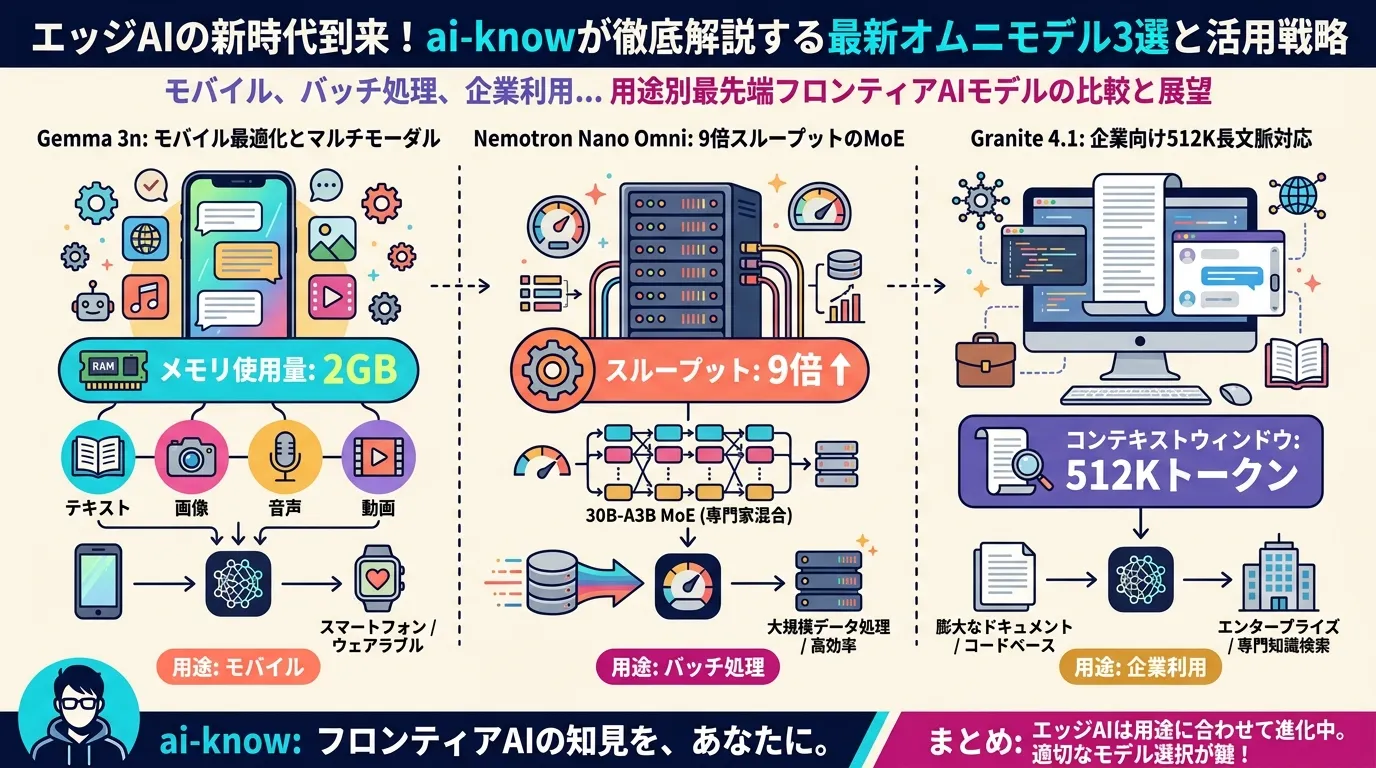
推論効率(Inference Efficiency)
LLM の推論フェーズ(ユーザーのリクエストに対して出力を生成する段階)において、計算コスト・メモリ消費・レイテンシを最小化しながら品質を維持する技術・指標の総称。代表的な手法として、量子化(重みを低ビット数で表現)・KVキャッシュ圧縮・MoE(Mixture-of-Experts)による疎な活性化・蒸留・推論フレームワーク最適化(vLLM・TensorRT-LLM など)がある。
2026年前半には TurboQuant(KVキャッシュ3ビット圧縮・H100で最大8倍高速化)や Mamba-Transformer ハイブリッドアーキテクチャなど、推論効率を飛躍的に向上させる技術が相次いで発表された。エッジデバイス上でのマルチモーダル推論の普及を左右する中心的なボトルネックとなっている。