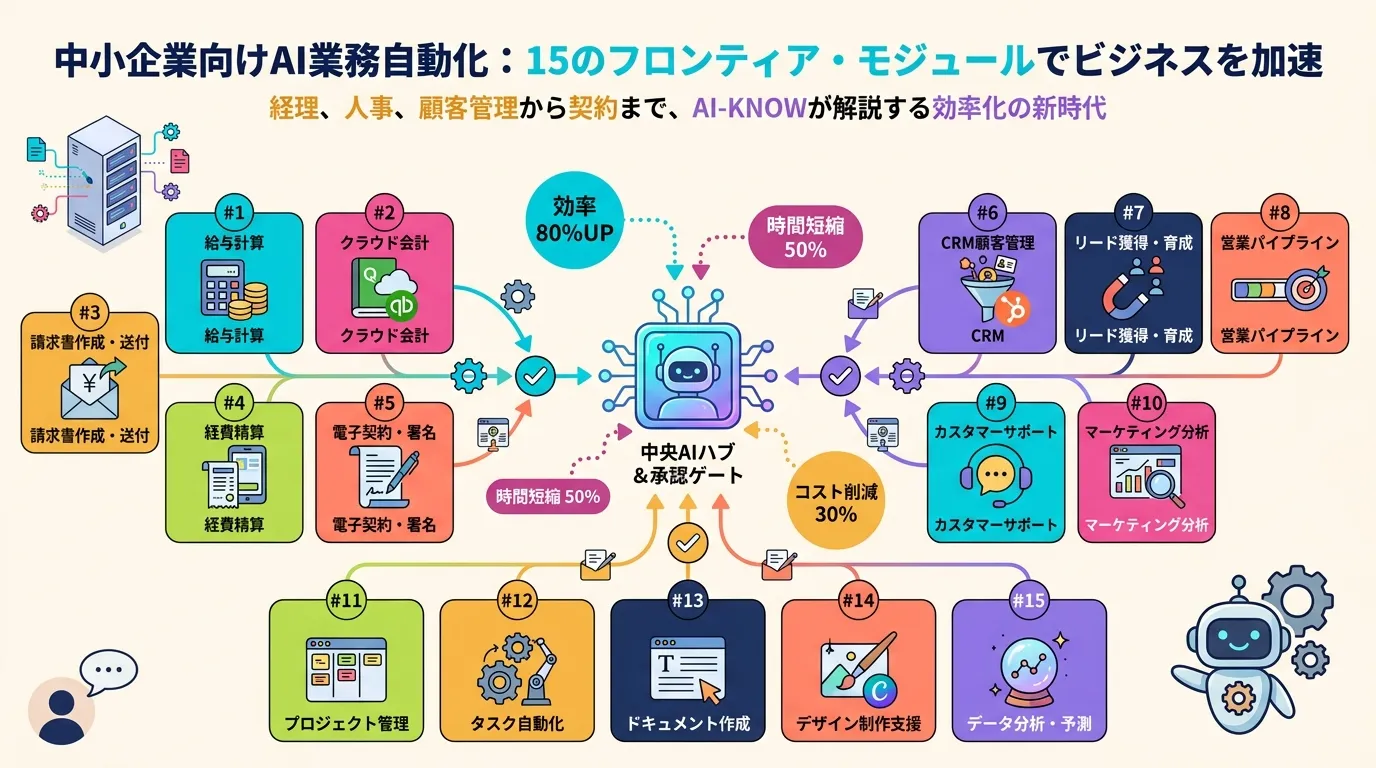
エッジ向けオムニモデルの現在地 2026 — Gemma 3n / Nemotron Nano Omni / Granite 4.1 を用途別に比較する
2GBのメモリでテキスト・画像・音声・動画を処理できる時代が来た。3つの主要エッジモデルをアーキテクチャ・メモリ・用途適性の軸で整理する
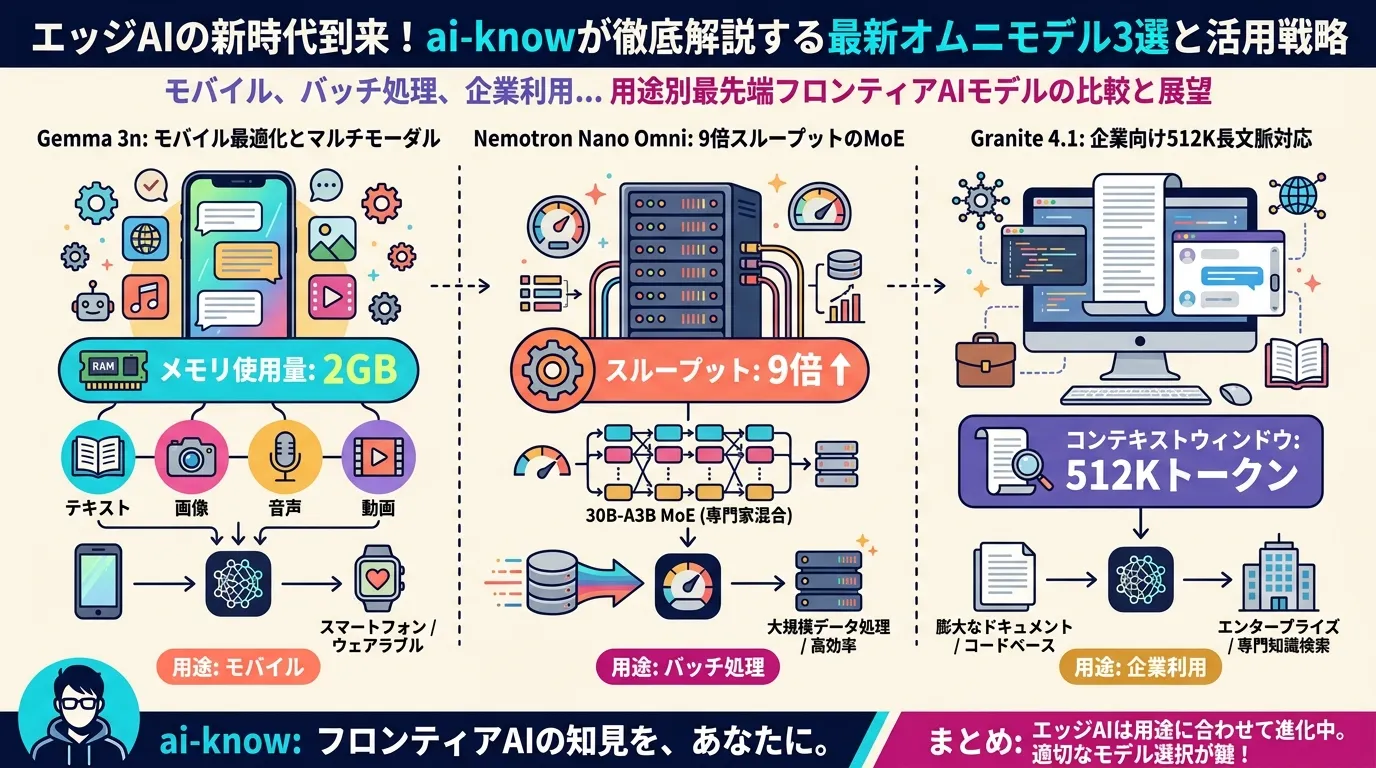
2026年4月、エッジAI向けの マルチモーダル LLM が一気に出揃った。Google DeepMind の Gemma 3n(MatFormer採用・2GBメモリ動作)、NVIDIA の Nemotron 3 Nano Omni(30B-A3B・既存比9倍スループット)、IBM の Granite 4.1(512Kコンテキスト・ISO 42001認証)——三者は設計思想を大きく異にしながら、「クラウドなしでマルチモーダルAIを動かしたい」という同じ需要を狙う。どのモデルをどの場面で選ぶべきか、アーキテクチャと用途の観点から整理する。
現状の主要プレイヤー
Gemma 3n E4B(Google DeepMind)
Gemma 3n E4B は Google DeepMind が2026年4月28日に開発者ガイドを公開した次世代エッジモデル。最大の特徴は MatFormer(Matryoshka Transformer) アーキテクチャだ。大きなモデルの中に小さなモデルが入れ子になる構造で、デバイスのリソース状況に応じてモデルサイズを動的に切り替える「弾力的推論(elastic inference)」を実現する。
E2B(実効2B・メモリ2GB)と E4B(実効4B・メモリ3GB)の2サイズで提供され、テキスト・画像・音声・動画の4モダリティに対応。140言語のテキスト理解と35言語のマルチモーダル理解をサポートし、Qualcomm・MediaTek・Samsung との共同最適化によりスマートフォン上でのオンデバイス推論を念頭に設計されている。E4B は LMArena スコア1300以上を達成した10B未満初のモデルとされ、エッジモデルとして異例の品質水準を誇る。
Apache 2.0ライセンスで商用利用可能。HuggingFace・Ollama から即座に入手できる。
Nemotron 3 Nano Omni(NVIDIA)
Nemotron 3 Nano Omni は NVIDIA が同日(2026年4月28日)に発表したエージェント向けオムニモデル。総パラメータ30B・アクティブパラメータ3Bという 30B-A3B 型 Mixture of Experts (MoE) 構成で、視覚・音声・言語の3モダリティを単一モデルに統合した。
Mamba-Transformer ハイブリッドバックボーン(長文脈で線形コスト)+ C-RADIOv4-H 視覚エンコーダ + Parakeet-TDT 音声エンコーダの三層構成で、既存オープンオムニモデル比で最大9倍のスループットを実証。131Kトークンのコンテキスト長に加え、CoT推論・ツールコール・JSON出力・単語レベルの音声タイムスタンプなど エージェント型 AI 用途に必要な機能を一通り備える。Amazon SageMaker・OpenRouter・HuggingFace など25以上のプラットフォームで即日利用可能だ。
文書OCR・会議音声の要約・長時間動画理解のような大量バッチ処理で特に真価を発揮する。「100点の精度より10倍の処理速度」を優先するユースケースに最適だ。
Granite 4.1 8B(IBM Research)
Granite 4.1 8B は IBM Research が2026年4月29日に Apache 2.0 で公開した オープンソース LLM ファミリー。3B・8B・30B の dense decoder-only 言語モデルを中核に、Vision 4.1(文書・チャート理解)・Granite Speech 4.1(多言語ASR)・Guardian 4.1(安全分類)・Embedding Multilingual R2(200言語・97M)のサテライトで構成される。
差別化の核心は2点。第一に 512Kトークンのコンテキスト窓(主要エッジモデル中で最長)。第二に ISO 42001 認証取得(AIマネジメントシステム国際規格、同カテゴリで世界初)。ベンチマークでは 8B dense が 32B-A9B MoE を大半のタスクで上回り、「小さいのに高品質」を数字で示している。
FP8対応の vLLM バリアントを同梱し、推論効率 の高いデプロイが即座に可能。暗号署名によるモデル系譜追跡機能は、金融・医療・公共といった規制産業での利用を見据えた設計だ。
比較表:用途別に整理
| 項目 | Gemma 3n E4B | Nemotron 3 Nano Omni | Granite 4.1 8B |
|---|---|---|---|
| アクティブパラメータ | 4B相当(実体5B) | 3B(総30B MoE) | 8B dense |
| 最小メモリ目安 | 3GB | DGX Spark以上推奨 | 〜16GB(FP8で削減可) |
| 対応モダリティ | テキスト・画像・音声・動画 | テキスト・画像・音声 | テキスト+サテライト |
| コンテキスト長 | 128K | 131K | 512K |
| ライセンス | Apache 2.0(Gemma利用規約) | Apache 2.0 | Apache 2.0 |
| ISO 42001 認証 | なし | なし | あり(同カテゴリ初) |
| 最適ユースケース | モバイル・プライバシー保護 | 高スループットバッチ | 長文書・規制対応 |
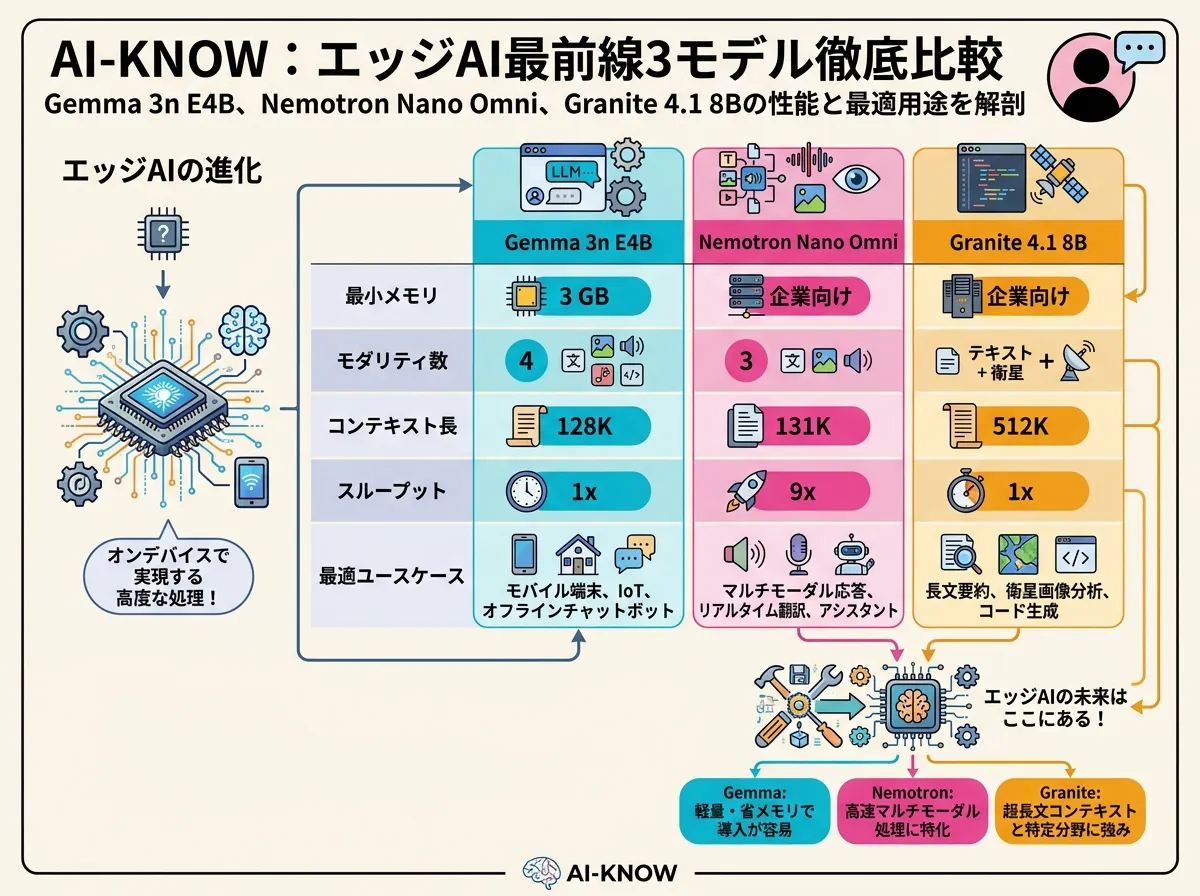
使い分けの推奨
モバイル・IoTデバイス(スマートフォン・Raspberry Pi・2〜4GB RAM環境)では Gemma 3n E4B が第一選択。MatFormerの弾力的推論がデバイスリソースに動的に適応し、プライバシー保護型のオフライン動作と多言語対応が際立つ。動画まで含む4モダリティをオンデバイスで処理できるモデルは現時点で唯一だ。
大量バッチ処理・エージェントのperceptionサブ(音声議事録・文書OCR・監視映像分析)では Nemotron 3 Nano Omni が最適。Mamba-Transformer ハイブリッドが長文脈の音声・動画処理に強く、30B-A3BというMixture of Experts (MoE)効率で9倍スループットのアドバンテージが出る。
エンタープライズ・規制産業の長文書処理・コンプライアンス用途は Granite 4.1 8B。512Kコンテキスト・ISO 42001認証・暗号署名系譜追跡という三点セットは他のエッジモデルが持たない組み合わせだ。
2026年の見通し
MatFormer・MoE・Mamba-Transformerという3つのアーキテクチャが「何GBのメモリで何モダリティ・何倍スループット」を競う構図は、2026年後半も激化するだろう。
注目点は2つ。Qualcomm AI Hub や Apple Silicon への Gemma 3n 最適化(2026年Q3目標)が深まれば、スマートフォン単体での4モダリティAIが一般ユーザーに届く転換点となる。一方、Nemotron Omni の後継モデルが WorldSense・DailyOmni などのエージェント系ベンチマークでどこまで伸ばすかが、エージェント向けオムニモデルの実用水準を測る指標になる。
推論効率 の改善ペースが、エッジAI普及の速度を直接規定するフェーズに入っている。
参考:Gemma 3n デベロッパーガイド(Google DeepMind, 2026)、Nemotron 3 Nano Omni 発表(NVIDIA Blog, 2026)、Granite 4.1 ファミリー(HuggingFace / IBM, 2026)、Nemotron Nano Omni 詳細(The Next Web, 2026)、Nemotron Omni 技術解説(NVIDIA Technical Blog, 2026)、Gemma 3n 紹介(Google Developers Blog, 2026)、April 2026 AI Models Review(Medium, 2026)
関連記事
宇宙 AI インフラ 2026 — Google・SpaceX・Cowboy Space・Blue Origin の軌道上計算レース比較
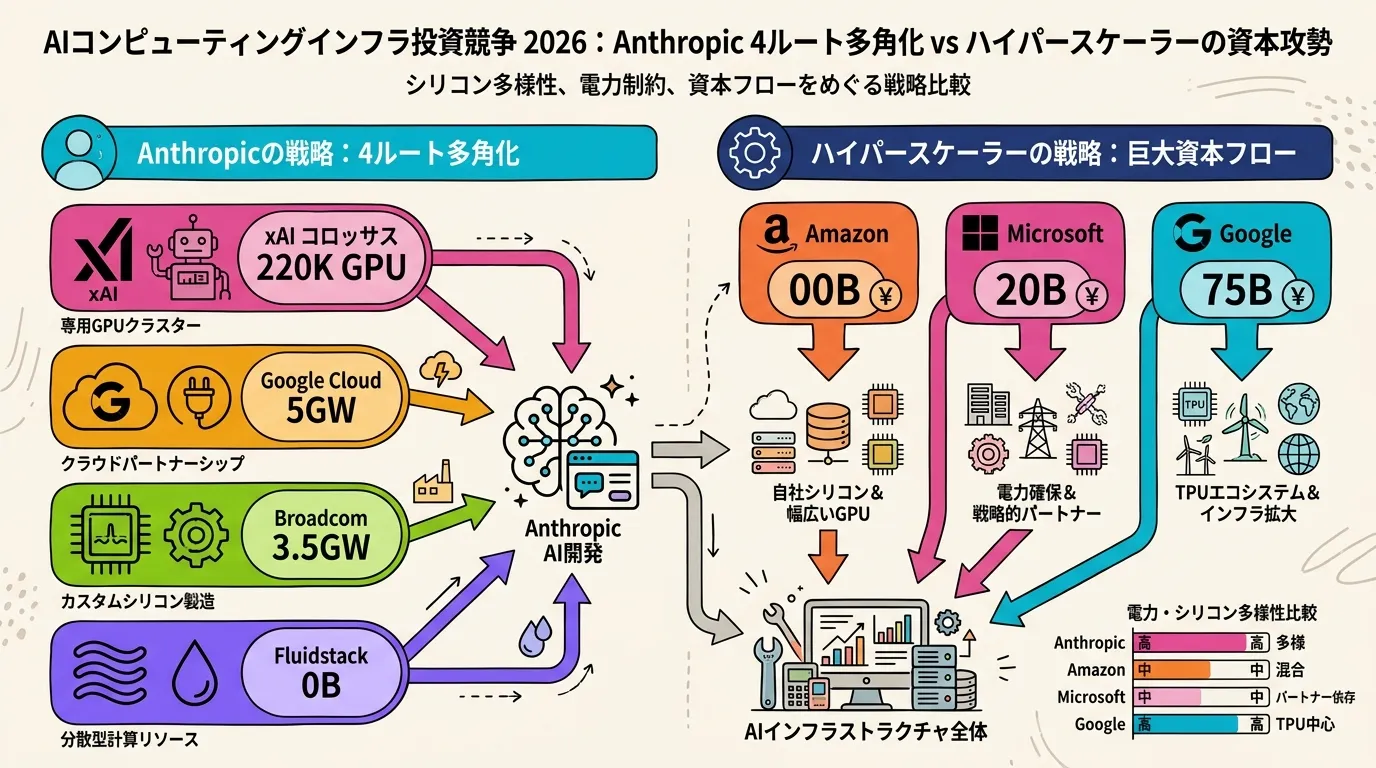
AI 計算インフラ投資の現在地 2026 — Anthropic 500 億ドル / xAI Colossus / Google-Broadcom を比較する
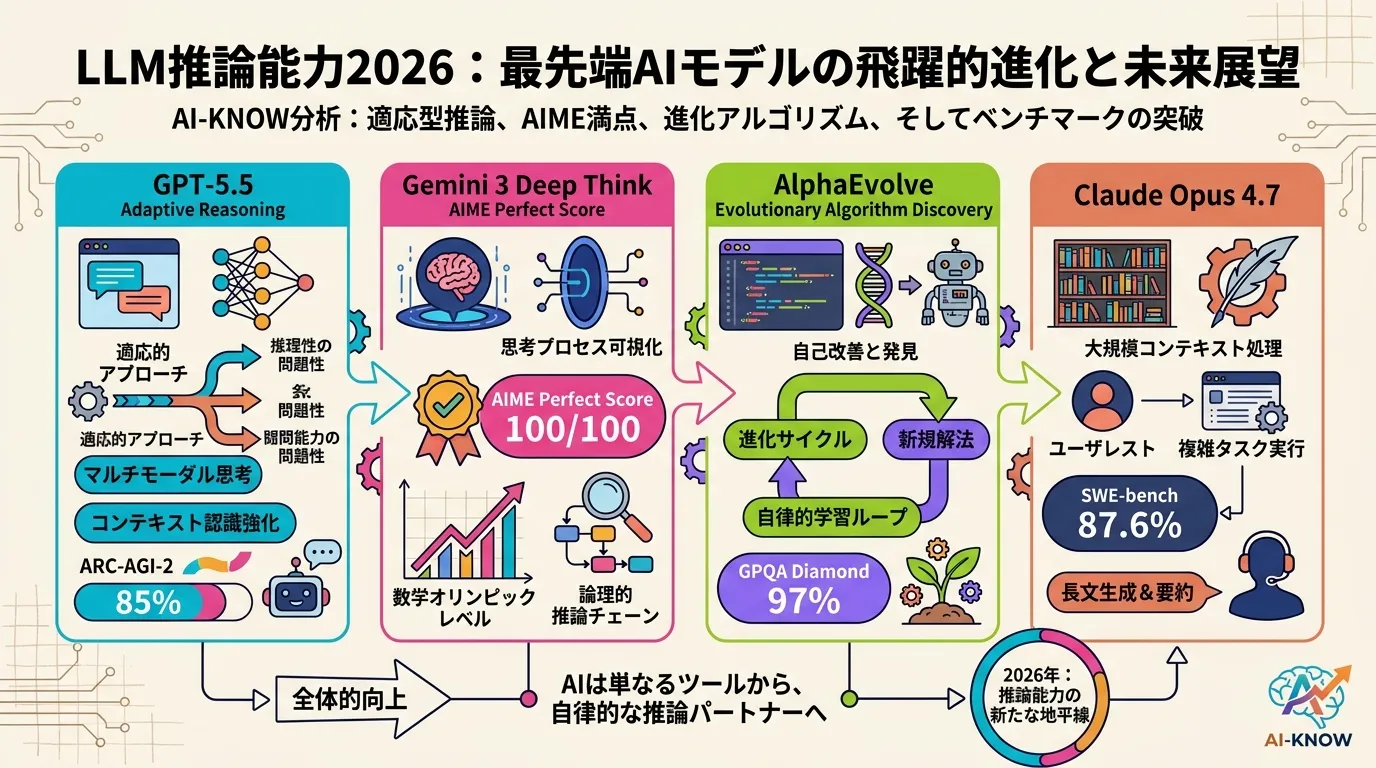
LLM 推論能力の現在地 2026 — GPT-5.5 / Gemini 3 Deep Think / AlphaEvolve を比べる

AI 評価インフラの現在地 2026 — MMLU 飽和から HAL・SWE-bench Pro・HLE まで、ベンチマーク選択の実践ガイド
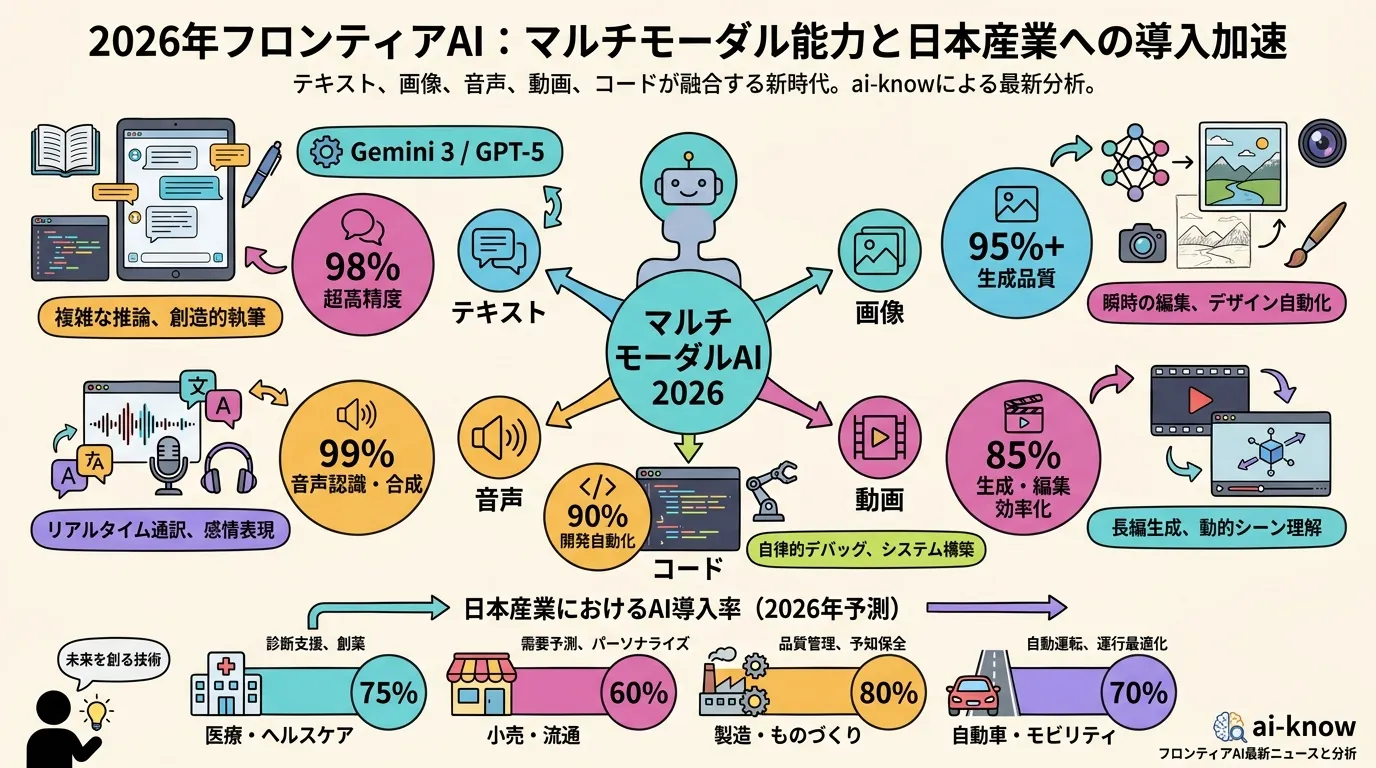
マルチモーダル LLM は「必須インフラ」へ — 2026 年の国内採用動向と native multimodal 設計の台頭