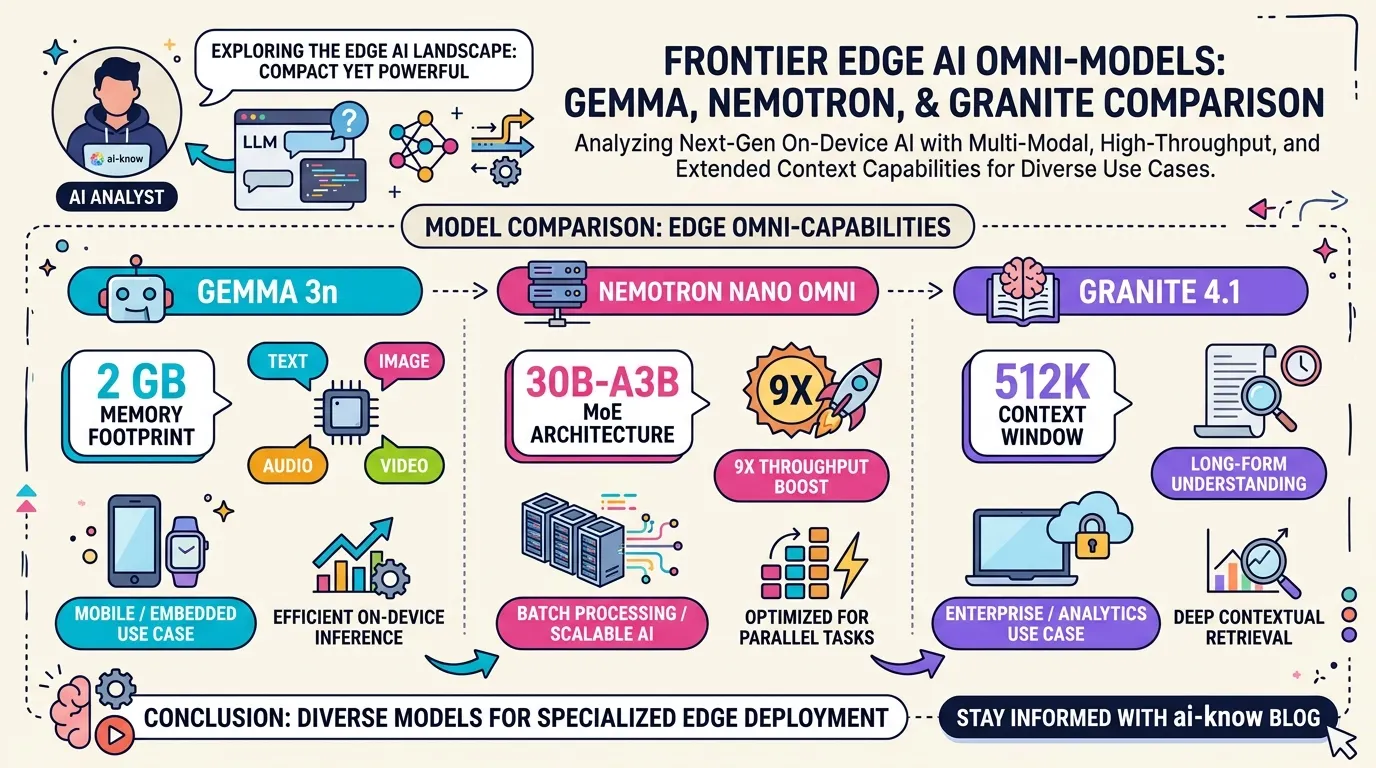
Inference Efficiency
The set of techniques and metrics aimed at minimizing compute cost, memory consumption, and latency during the inference phase of an LLM — the step of generating outputs in response to user requests — while preserving output quality. Key approaches include weight quantization (representing model weights in fewer bits), KV cache compression, Mixture-of-Experts (MoE) sparse activation, model distillation, and inference framework optimization (vLLM, TensorRT-LLM, etc.).
In early 2026, techniques such as TurboQuant (3-bit KV cache compression, up to 8× speedup on H100) and Mamba-Transformer hybrid architectures dramatically raised the efficiency ceiling. Inference efficiency has become the primary bottleneck determining the pace of edge multimodal AI adoption.