マルチモーダル LLM(Multimodal LLM)
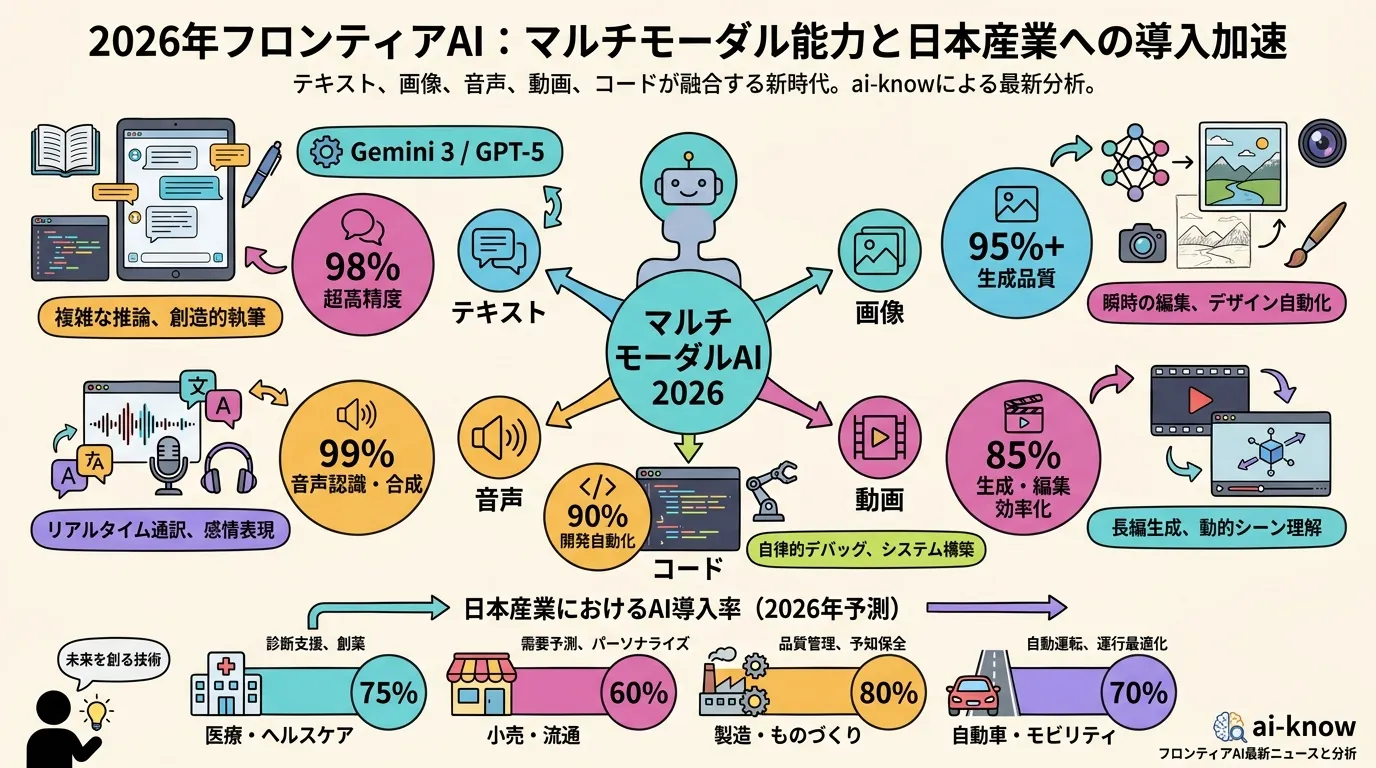
テキストだけでなく、画像・音声・動画など複数のモダリティ(情報様式)を入力として扱える大規模言語モデル(LLM)の総称。従来のテキスト専用 LLM に対して、視覚エンコーダや音声エンコーダを統合することで、写真の説明・音声の書き起こし・動画の要約といったタスクを単一モデルで処理できる。
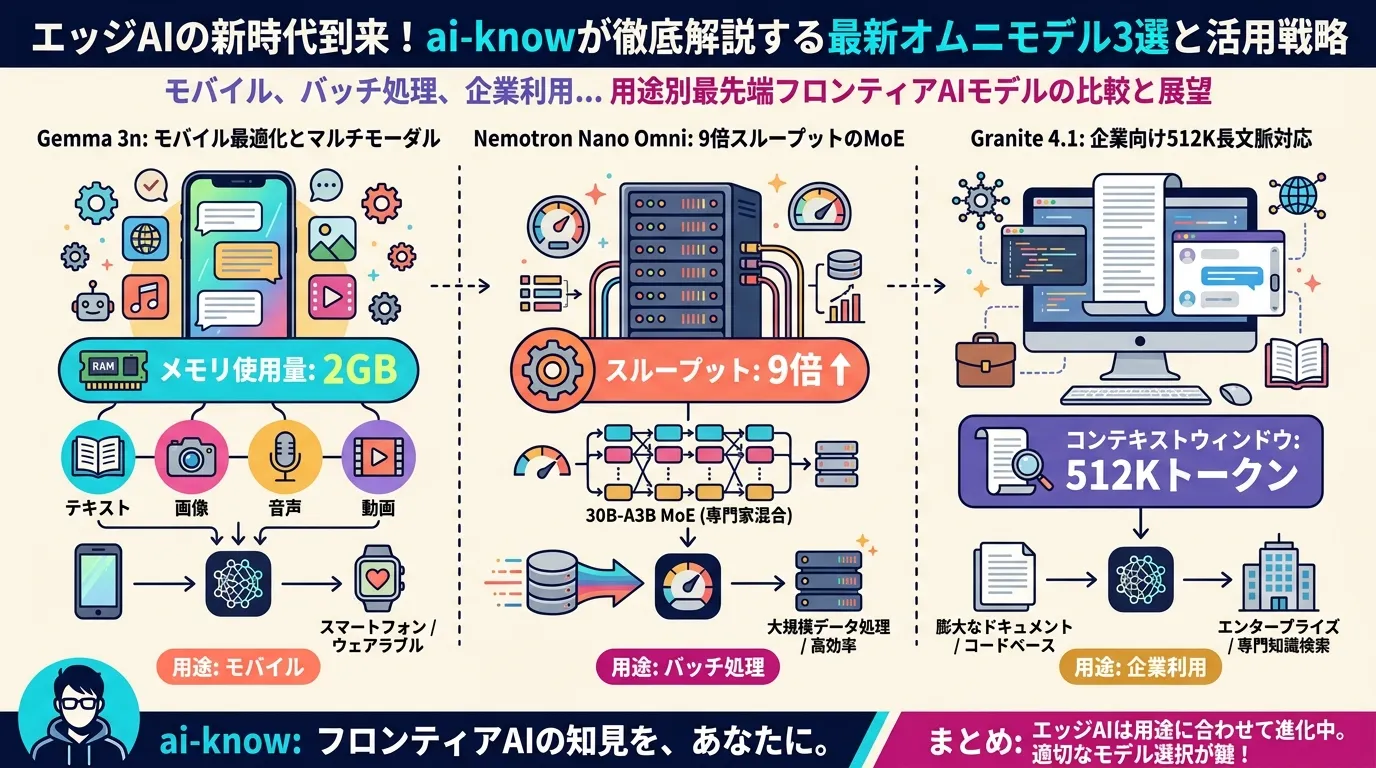
2024年以降のフロンティアモデルでは、マルチモーダル対応が事実上の標準機能となっており、GPT-4o・Gemini 1.5・Claude 3・Gemma 4 などが代表例として挙げられる。2026年には edge 向けの軽量マルチモーダルモデル(Gemma 3n・Nemotron Nano Omni など)が登場し、クラウドなしのオンデバイス推論でも4モダリティを処理できる段階に達している。