Multimodal LLM
A large language model (LLM) capable of processing multiple modalities of input — including text, images, audio, and video — rather than text alone. Multimodal LLMs integrate dedicated encoders (e.g., a vision transformer or audio encoder) alongside the core language backbone, enabling a single model to describe images, transcribe speech, and summarize video in one unified architecture.
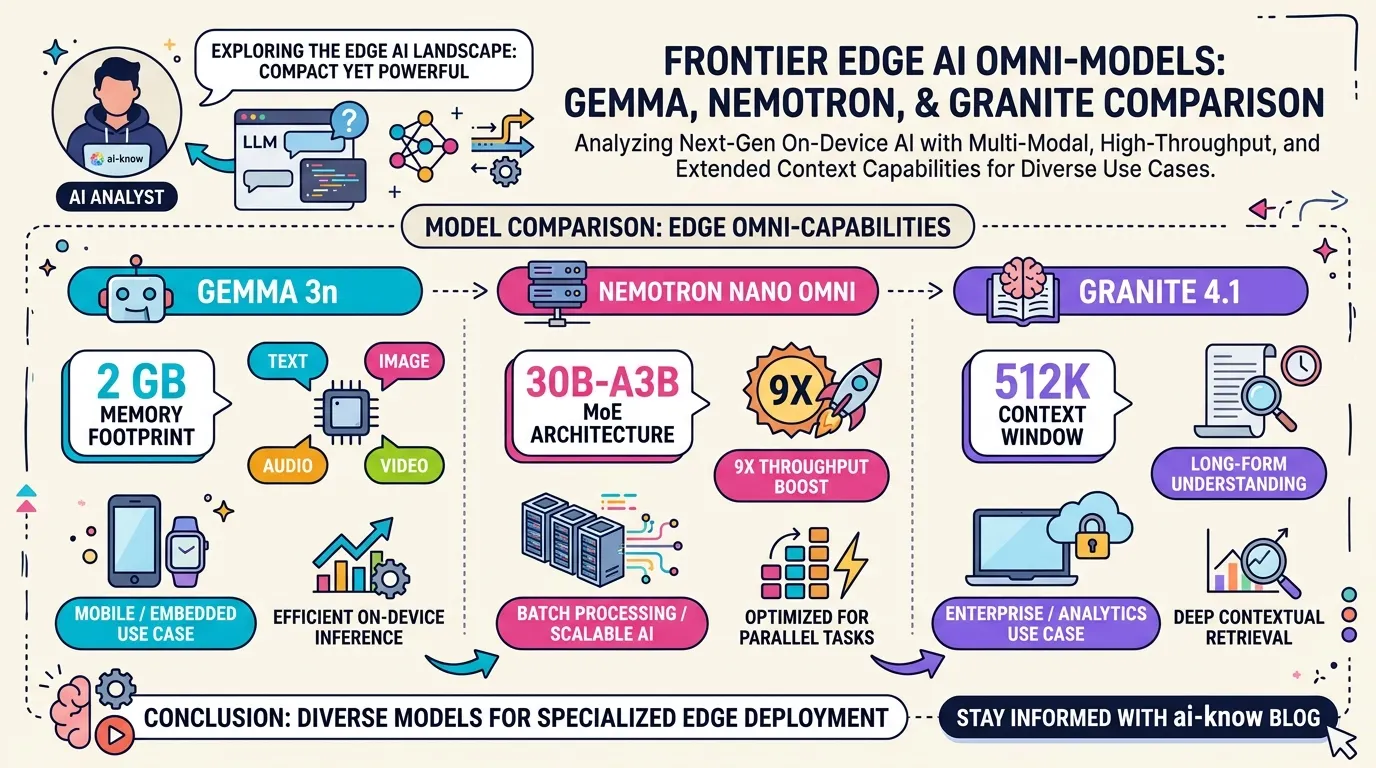
Since 2024, multimodal capability has become a de facto standard in frontier models (GPT-4o, Gemini 1.5, Claude 3, Gemma 4). By 2026, lightweight edge multimodal models such as Gemma 3n and Nemotron Nano Omni have extended four-modality processing to on-device environments running in as little as 2 GB of RAM.