Edge Omni Models in 2026: Gemma 3n, Nemotron Nano Omni, and Granite 4.1 Compared
Multimodal AI now runs in 2 GB of RAM. We break down the three leading edge models across architecture, memory, and deployment fit.
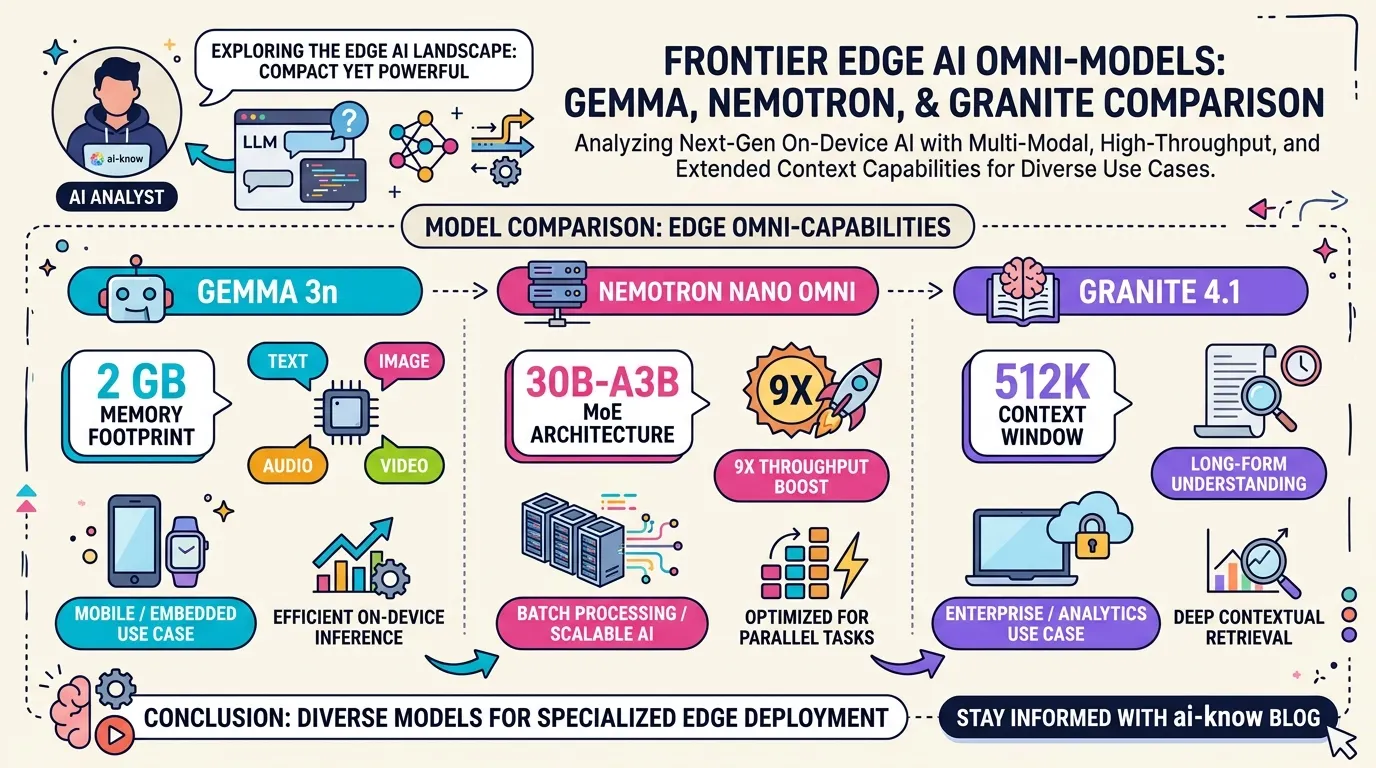
April 2026 brought a wave of edge-ready Multimodal LLM models to the open-source ecosystem. Google DeepMind‘s Gemma 3n (MatFormer architecture, runs in 2 GB of RAM), NVIDIA‘s Nemotron 3 Nano Omni (30B-A3B MoE, 9× throughput over comparable open omni models), and IBM‘s Granite 4.1 (512 K-token context, ISO 42001 certified) all target the same fundamental need: running multimodal AI without a cloud dependency. Their design philosophies differ sharply. Here is how to choose.
The Main Contenders
Gemma 3n E4B (Google DeepMind)
Gemma 3n E4B is Google DeepMind’s on-device multimodal model, whose developer guide landed on April 28, 2026. The headline feature is the MatFormer (Matryoshka Transformer) architecture: a nested transformer design where a larger model contains fully functional smaller models, enabling elastic inference — the ability to dynamically resize the model at runtime based on available device resources.
Two sizes are available: E2B (effective 2 B parameters, 2 GB memory footprint) and E4B (effective 4 B, 3 GB). Both handle text, image, audio, and video — four modalities — with 140-language text comprehension and 35-language multimodal understanding. The model was co-optimized with Qualcomm, MediaTek, and Samsung for smartphone and tablet deployment. E4B is reported as the first sub-10 B model to exceed an LMArena score of 1300, an unusual achievement for an edge model.
License: Apache 2.0 (with Gemma terms of use). Available immediately on HuggingFace and Ollama.
Nemotron 3 Nano Omni (NVIDIA)
Nemotron 3 Nano Omni, launched the same day (April 28), is NVIDIA’s open omni model purpose-built for agentic workloads. The architecture is a 30B-A3B Mixture of Experts (MoE) design: 30 B total parameters, 3 B active per inference step, yielding frontier-quality reasoning at 3 B inference cost.
Under the hood: a Mamba-Transformer hybrid backbone (linear complexity for long contexts) paired with a C-RADIOv4-H vision encoder and a Parakeet-TDT audio encoder. This combination handles text, images, and audio with a 131 K-token context window. NVIDIA benchmarks show up to 9× the throughput of comparable open omni models. Beyond raw speed, Nemotron Omni ships with chain-of-thought reasoning, tool calls, JSON output, and word-level audio timestamps — the full toolkit for Agentic AI perception agents.
Available on 25+ platforms including Amazon SageMaker, OpenRouter, and HuggingFace from day one.
Granite 4.1 8B (IBM Research)
Granite 4.1 8B is IBM Research’s enterprise-grade open model family, released under Apache 2.0 on April 29, 2026. The core consists of dense decoder-only language models at 3 B, 8 B, and 30 B, augmented by a set of specialized satellites: Vision 4.1 (document and chart understanding), Granite Speech 4.1 (multilingual ASR), Guardian 4.1 (safety classification), and Embedding Multilingual R2 (200 languages, 97 M parameters).
Two differentiators stand out. First, a 512 K-token context window — the longest among the three models reviewed here. Second, ISO 42001 certification (the AI management system standard), which Granite 4.1 is first in its category to achieve. Benchmark results show the 8 B dense model outperforming a 32 B-A9 B MoE on most tasks, backed by approximately 15 T tokens of multi-stage pretraining.
Deployment is frictionless for Inference Efficiency-focused teams: FP8-ready vLLM variants are bundled, and cryptographic model-lineage tracking is built in for regulated industries.
Comparison Table
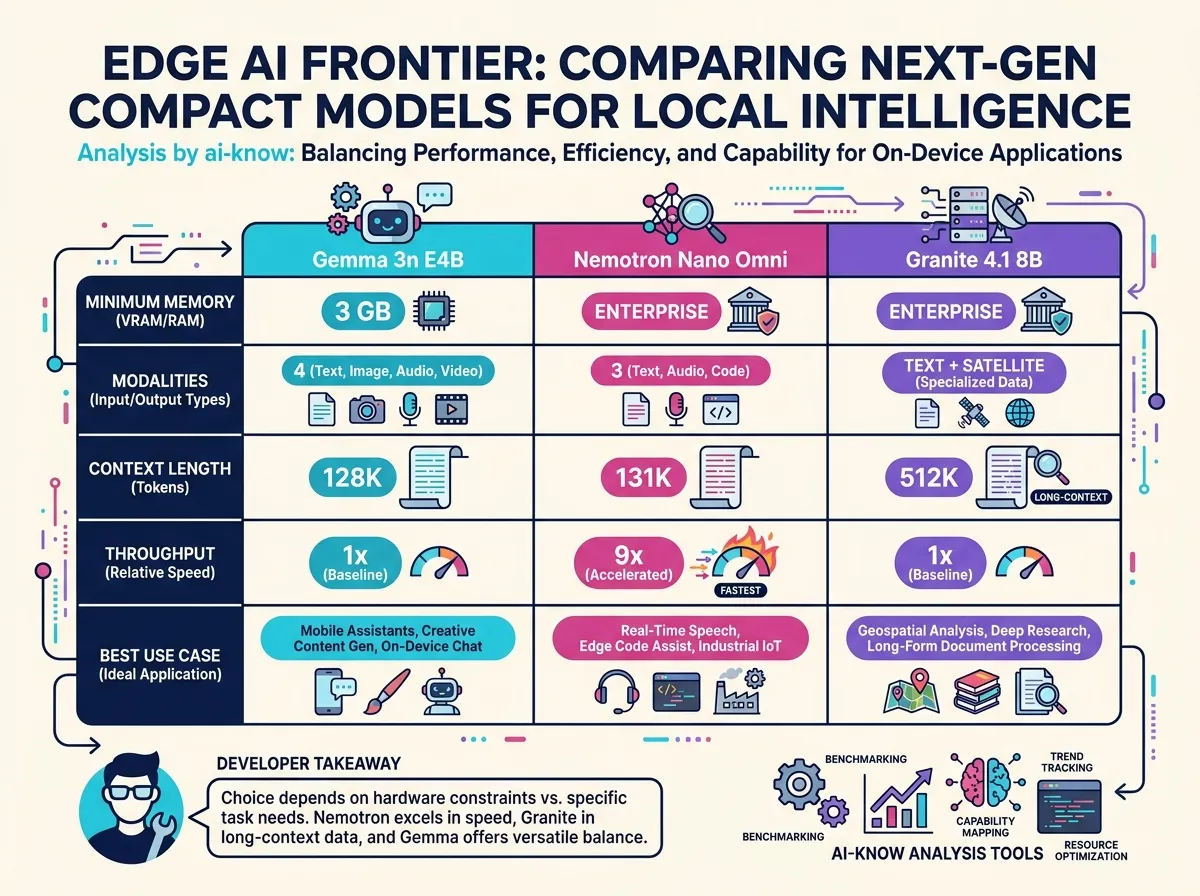
| Dimension | Gemma 3n E4B | Nemotron 3 Nano Omni | Granite 4.1 8B |
|---|---|---|---|
| Active parameters | ~4 B (raw 5 B) | 3 B active (30 B total MoE) | 8 B dense |
| Minimum memory | 3 GB | DGX Spark or higher | ~16 GB (reducible with FP8) |
| Modalities | Text, image, audio, video | Text, image, audio | Text + satellite models |
| Context length | 128 K | 131 K | 512 K |
| License | Apache 2.0 (Gemma ToS) | Apache 2.0 | Apache 2.0 |
| ISO 42001 certified | No | No | Yes (first in category) |
| Best fit | Mobile / offline / privacy | High-throughput batch | Long documents / compliance |
Deployment Recommendations
Mobile, IoT, and privacy-constrained devices (smartphones, Raspberry Pi, anything under 4 GB RAM): Gemma 3n E4B is the only real option today. MatFormer’s elastic inference adapts to device constraints at runtime; the four-modality coverage is unmatched at this memory budget; and offline operation eliminates cloud latency and data-egress risk.
High-throughput agentic pipelines (audio transcription at scale, document OCR, long-video analysis): Nemotron 3 Nano Omni is the clear winner. The Mamba-Transformer hybrid excels at sustained long-context audio and video workloads, and the 9× throughput advantage of the 30B-A3B Mixture of Experts (MoE) design is most visible at batch scale. Think “80 points at 10× speed” rather than “100 points.”
Enterprise and regulated industries (finance, healthcare, public sector, legal): Granite 4.1 8B is purpose-built here. The 512 K context window handles full contract reviews; ISO 42001 certification satisfies governance requirements; and cryptographic lineage tracking provides the audit trail that regulated workloads demand.
Outlook for 2026
The competition between MatFormer, MoE, and Mamba-Transformer architectures — each claiming the best tradeoff between memory, modality, and throughput — will only intensify through the rest of 2026.
Two milestones are worth watching. Google’s collaboration with Qualcomm and Samsung targets deeper Gemma 3n optimization for AI Hub hardware by Q3 2026; if that lands, four-modality on-device AI becomes an everyday smartphone feature. On the agent side, Nemotron Omni’s successor models and their scores on WorldSense and DailyOmni will set the benchmark for what a perception agent can reliably handle in production.
The pace of Inference Efficiency improvement is now the direct governor of edge AI adoption.
Sources: Gemma 3n Developer Guide (Google DeepMind, 2026); Nemotron 3 Nano Omni Launch (NVIDIA Blog, 2026); Granite 4.1 Family (HuggingFace / IBM, 2026); Nvidia Nemotron Nano Omni overview (The Next Web, 2026); Nemotron Omni Technical Deep Dive (NVIDIA Technical Blog, 2026); Gemma 3n Introduction (Google Developers Blog, 2026); April 2026 AI Models Review (Medium, 2026)
Related Articles
Space-Based AI Infrastructure 2026: Comparing Google, SpaceX, Cowboy Space, and Blue Origin in the Race to Orbit
AI Compute Infrastructure 2026: Anthropic's $50B Pledge, the xAI Colossus Deal, and Google-Broadcom's 8.5GW Bet
State of LLM Reasoning 2026: Comparing GPT-5.5, Gemini 3 Deep Think, and AlphaEvolve
AI Evaluation in 2026: Beyond MMLU — A Practical Guide from SWE-bench Pro to HLE
Multimodal LLMs Become Essential Infrastructure: Japan Adoption Trends and the Native Multimodal Shift in 2026