LLM Evaluation(LLM Evaluation)
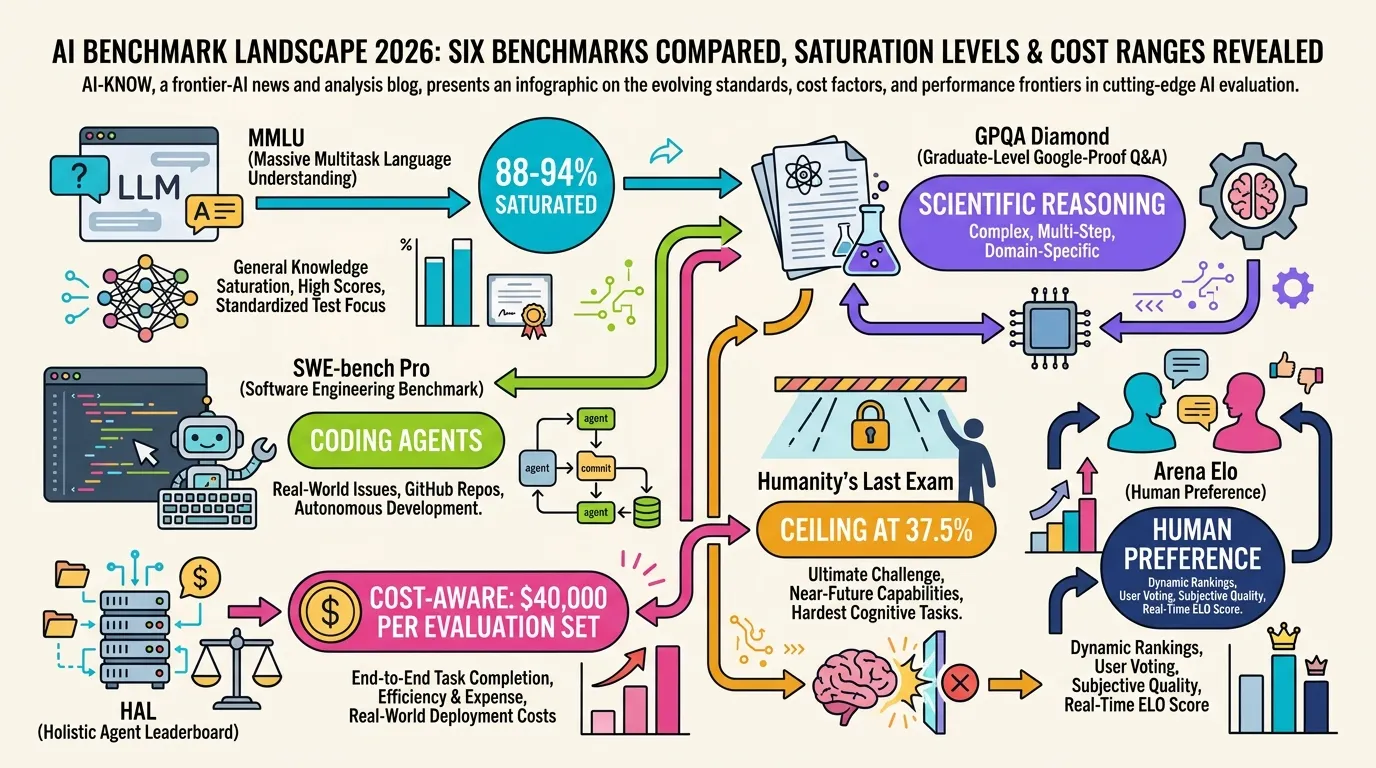
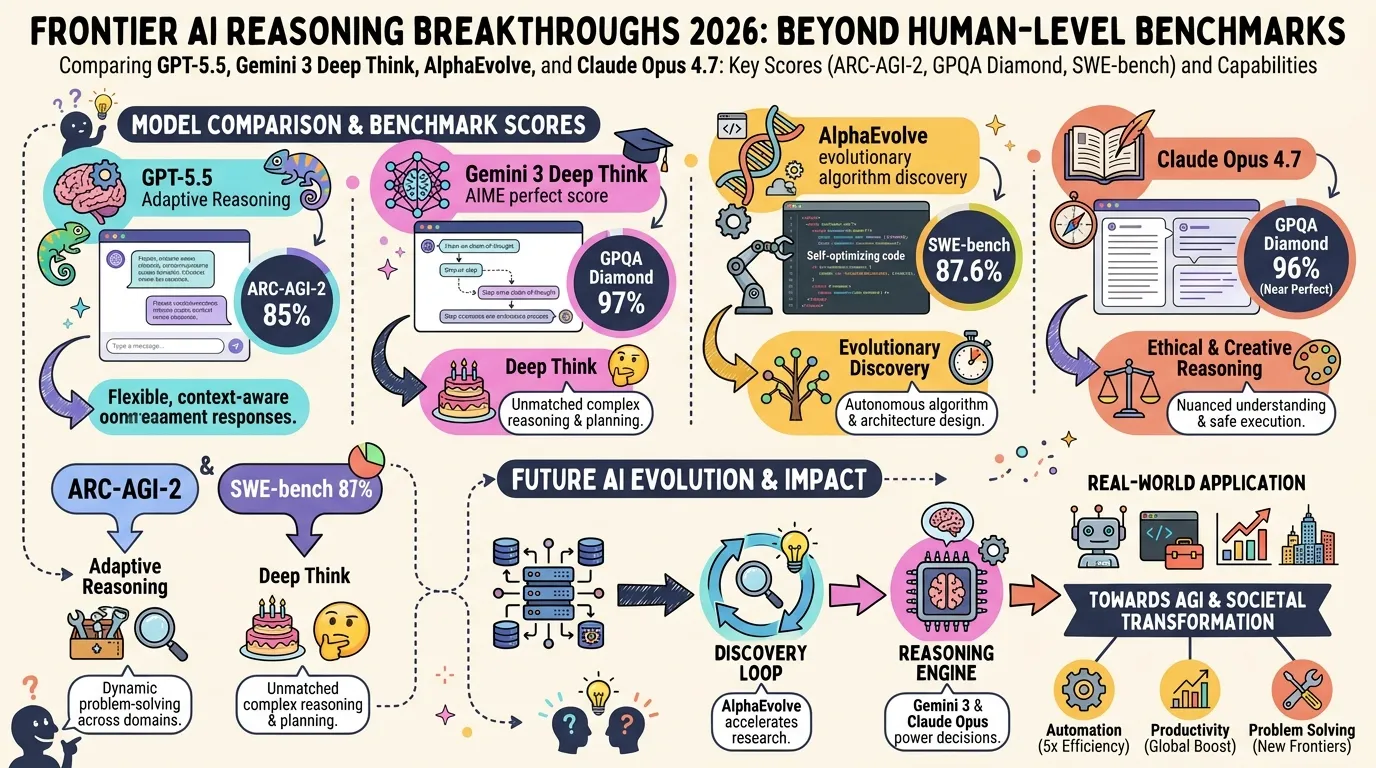
LLM Evaluation refers to the benchmarks, methodologies, and infrastructure used to quantitatively assess large language model capability, quality, and cost. In 2026, MMLU saturation and SWE-bench Verified contamination issues have accelerated adoption of newer benchmarks including GPQA Diamond, SWE-bench Pro, and Humanity’s Last Exam (HLE).
※ Auto-generated stub — requires completion