State of LLM Reasoning 2026: Comparing GPT-5.5, Gemini 3 Deep Think, and AlphaEvolve
AIME perfect scores, IMO gold, and 85% on ARC-AGI-2 — mapping the frontier of machine reasoning in 2026
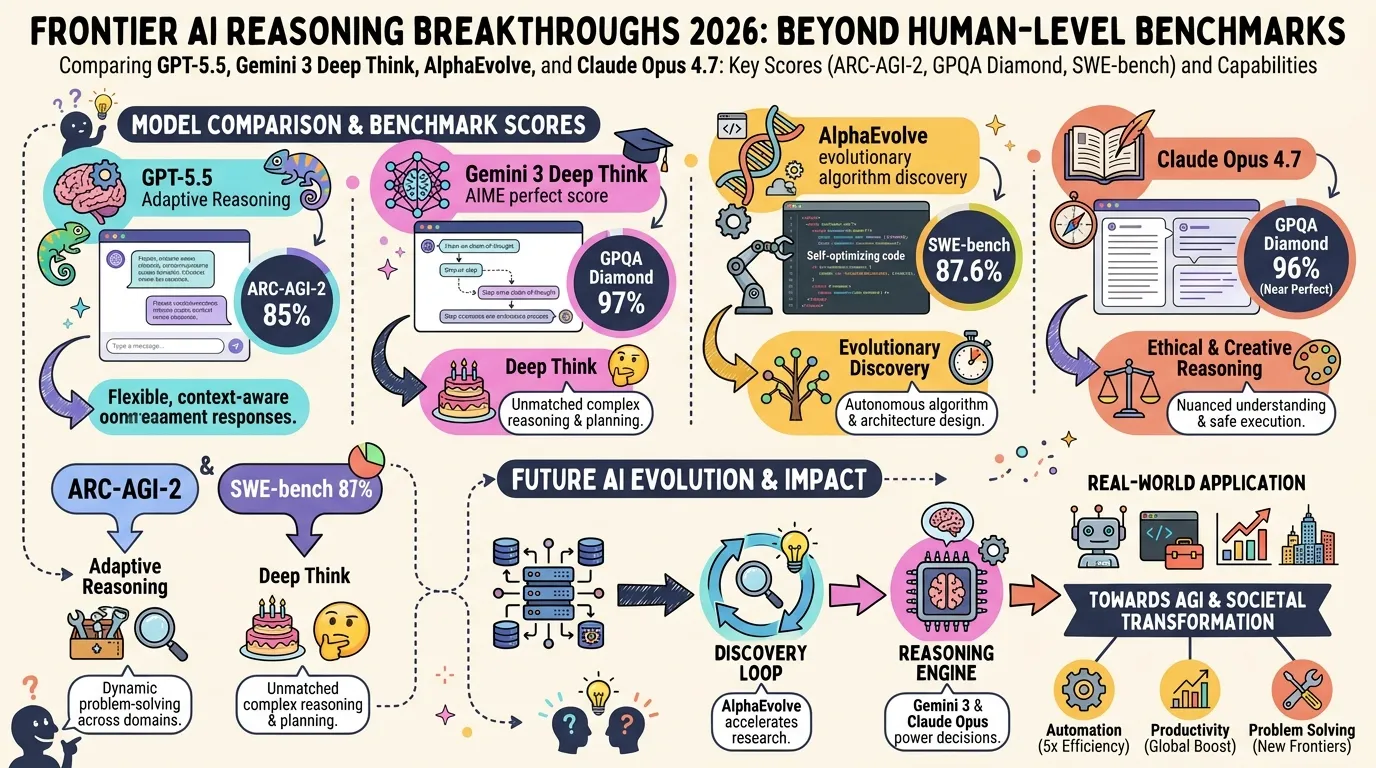
Frontier AI benchmarks finally have teeth in 2026. The MMLU and HumanEval era is over — leading models saturated those at 90%+ years ago. What replaced them are harder targets: AIME (math competition qualifying rounds), GPQA Diamond (PhD-level science), and ARC-AGI-2 (abstract rule discovery tasks designed to resist memorization).
Yet the question “which model reasons best?” resists a simple leaderboard answer. Reasoning Models have split into at least three distinct schools: deep chain-of-thought (Gemini Deep Think), adaptive agentic reasoning (GPT-5.5), and evolutionary algorithm search (AlphaEvolve). Each excels on different tasks — and each has a distinct failure mode.
Key Players
GPT-5.5 (OpenAI)
GPT-5.5 launched on April 23, 2026, and became the default ChatGPT model on May 5. Its headline innovation is Adaptive Reasoning: the model automatically routes each prompt to either lightweight GPT-5.3 Instant or full GPT-5.5 Thinking, depending on assessed difficulty.
On ARC-AGI-2 it leads the public leaderboard at 85%. On Terminal-Bench 2.0 (multi-step agentic coding) it sits first at 82.7%. Compared to GPT-5.3 Instant, it produces 52.5% fewer hallucinated claims on high-stakes prompts in medicine, law, and finance. The architecture prioritizes long-context coherence across extended, multi-action sessions — precisely what autonomous agent workflows demand.
Gemini 3 Deep Think (Google DeepMind)
Gemini 3 Deep Think is the scientific reasoning specialist. It scores 99/100 on AIME 2023, earned a gold medal equivalent on IMO 2025, and achieves 97% on GPQA Diamond — beating GPT-5.4 (92.8%) and Gemini 3.1 Pro (94.3%). The 2M-token context window allows it to hold extended reasoning chains without truncation.
The trade-off is latency: Deep Think problems can take minutes to process. It is best understood as a reasoning tool for research tasks where accuracy is paramount and turnaround time is flexible — theorem proving, scientific hypothesis evaluation, complex mathematical derivations.
AlphaEvolve (Google DeepMind)
AlphaEvolve, announced in May 2026, is not a reasoning model in the conventional sense. Rather than “thinking through” a problem, it uses Google DeepMind‘s Gemini to generate candidate algorithms and an evolutionary search loop to iteratively improve them.
Across 50 open mathematical problems, AlphaEvolve rediscovered state-of-the-art solutions in 75% of cases and found genuinely improved solutions in 20%. In production: data center task scheduling improved by 0.7% globally; a core Gemini architecture kernel runs 23% faster; FlashAttention XLA execution improved by 32%. It also produced the first improvement to Strassen’s matrix multiplication algorithm in 56 years.
Claude Opus 4.7 (Anthropic)
Claude Opus 4.7 leads on multi-file code reasoning at 87.6% SWE-bench Verified — the highest score among all models on sustained software engineering tasks. On ARC-AGI-2, Claude Opus 4.6 (February 2026) recorded 68.8%, a dramatic jump from 8.6% on Opus 4 in May 2025, reflecting nine months of focused iteration. The architecture excels at maintaining coherent intent across long instruction chains.
Comparison Table
| Model | GPQA Diamond | ARC-AGI-2 | SWE-bench Verified | Reasoning approach |
|---|---|---|---|---|
| GPT-5.5 | — | 85.0% | 82.7% | Adaptive (fast/deep) |
| Gemini 3 Deep Think | 97.0% | — | — | Extended chain-of-thought |
| Claude Opus 4.7 | — | 68.8%* | 87.6% | Long-context coherence |
| GPT-5.4 Pro | 92.8% | 83.3% | — | — |
| Gemini 3.1 Pro | 94.3% | 77.1% | — | — |
*Claude Opus 4.6 score (February 2026); Opus 4.7 score not yet publicly disclosed.
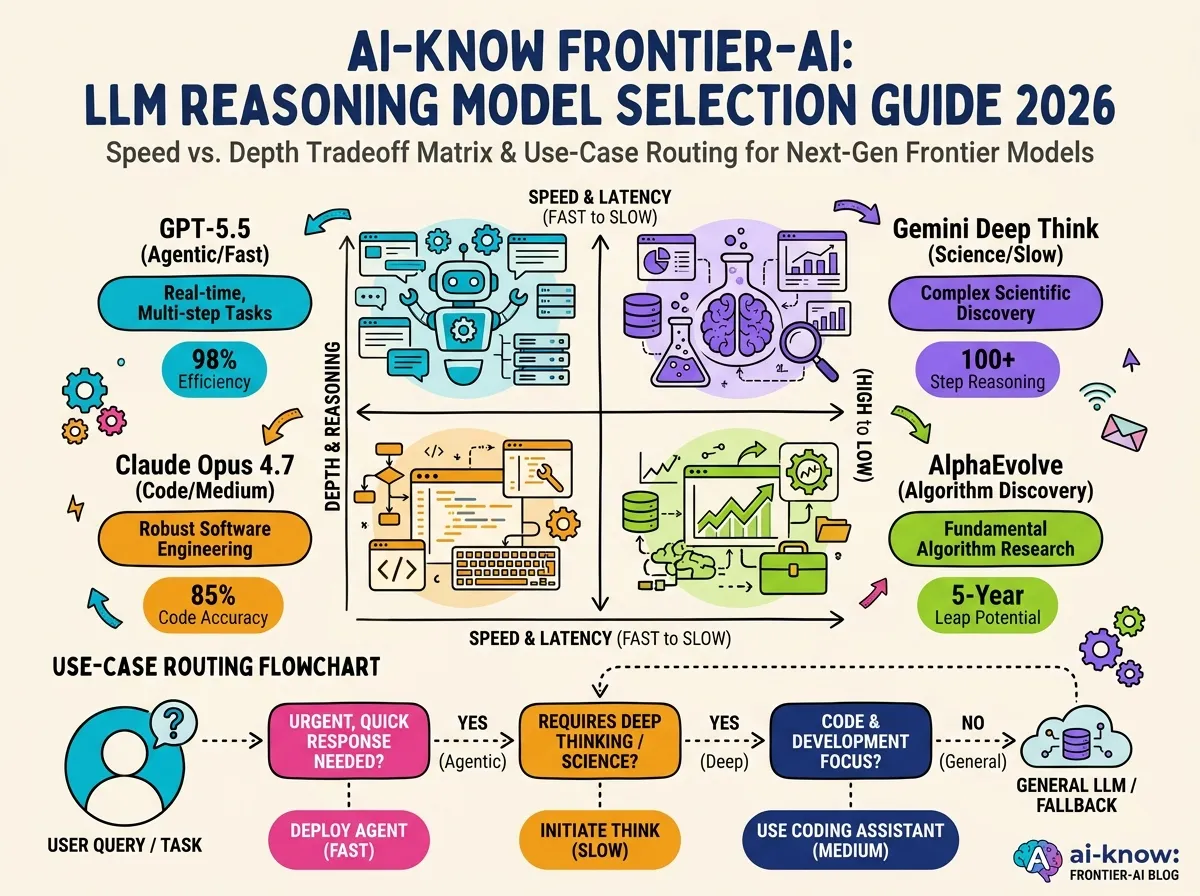
Which Model to Choose
Mathematical and scientific research — theorem proving, hypothesis evaluation, competition math: Gemini 3 Deep Think is the clear first choice. IMO gold and AIME 99 are not marketing claims; they reflect genuine capability for long, precise derivation chains. Accept the latency cost.
Agentic coding, autonomous workflows, long-horizon tasks: GPT-5.5 is the strongest all-around option. The 85% ARC-AGI-2 score demonstrates novel-structure recognition; the halved hallucination rate reduces cascading errors in multi-step pipelines. The Adaptive Reasoning routing also minimizes unnecessary compute spend.
Large-scale software engineering, multi-file codebases: Claude Opus 4.7 at 87.6% SWE-bench Verified is the benchmark leader. The long-context architecture handles sustained modification tasks that require tracking complex dependency chains without losing the original intent.
Algorithm discovery and optimization: AlphaEvolve is in a category of its own. If the goal is finding a better solution to a mathematical or computational problem — not just solving an instance — AlphaEvolve’s evolutionary search loop is the right tool. Google Cloud availability is expanding in H2 2026.
What’s Next in 2026
Test-time scaling deepens: Allocating more inference compute consistently raises accuracy on hard tasks. Process Reward Models (per-step feedback) and Reflective Agents (self-correction loops) are converging into a standard reasoning pipeline. The o1 → o3 → GPT-5.5 Thinking trajectory will likely continue.
Latent reasoning emerges: Multiple 2026 papers — Latent-GRPO, DeepLatent Reasoning, CoLaR — attempt to move reasoning from the token space into the embedding space. DeepLatent Reasoning cut hallucinated intermediate steps from 27% to 9% compared with token-level GRPO. If latent RL stabilizes, it offers a path to more efficient, less verbose reasoning chains.
Strategic reasoning remains hard: A May 2026 study (arxiv: 2605.00226) found that even frontier models exhibit a three-way dissociation between internal beliefs, verbal reports, and actual actions in strategic games. Models achieving 90%+ on atomic game tasks collapse to below 20% on compositionally complex structures. Chain-of-Thought alone does not close this gap.
Sources: Introducing GPT-5.5 (OpenAI, 2026), GPT-5.5 Instant (OpenAI, 2026), AlphaEvolve: A Gemini-powered coding agent (Google DeepMind, 2026), AlphaEvolve Impact (Google DeepMind, 2026), Gemini Deep Think: Accelerating scientific discovery (Google DeepMind, 2026), ARC-AGI-2 Technical Report (ARC Prize, 2026), Why Do LLMs Struggle in Strategic Play? (arxiv
.00226), Latent-GRPO (arxiv.27998), AI Trends 2026: Test-Time Reasoning (HuggingFace Blog), GPT-5 vs Gemini 2026 Full Benchmark Breakdown (BenchLM.ai)Related Articles
AI Evaluation in 2026: Beyond MMLU — A Practical Guide from SWE-bench Pro to HLE
AI Compute Infrastructure 2026: Anthropic's $50B Pledge, the xAI Colossus Deal, and Google-Broadcom's 8.5GW Bet

10 Charts That Explain AI in 2026: Progress, Adoption Gaps, and Backlash
Space-Based AI Infrastructure 2026: Comparing Google, SpaceX, Cowboy Space, and Blue Origin in the Race to Orbit
Edge Omni Models in 2026: Gemma 3n, Nemotron Nano Omni, and Granite 4.1 Compared