AI Evaluation in 2026: Beyond MMLU — A Practical Guide from SWE-bench Pro to HLE
With a single evaluation run costing $40,000 and a 9x cost gap producing 2 points of accuracy difference, choosing benchmarks is now a business decision
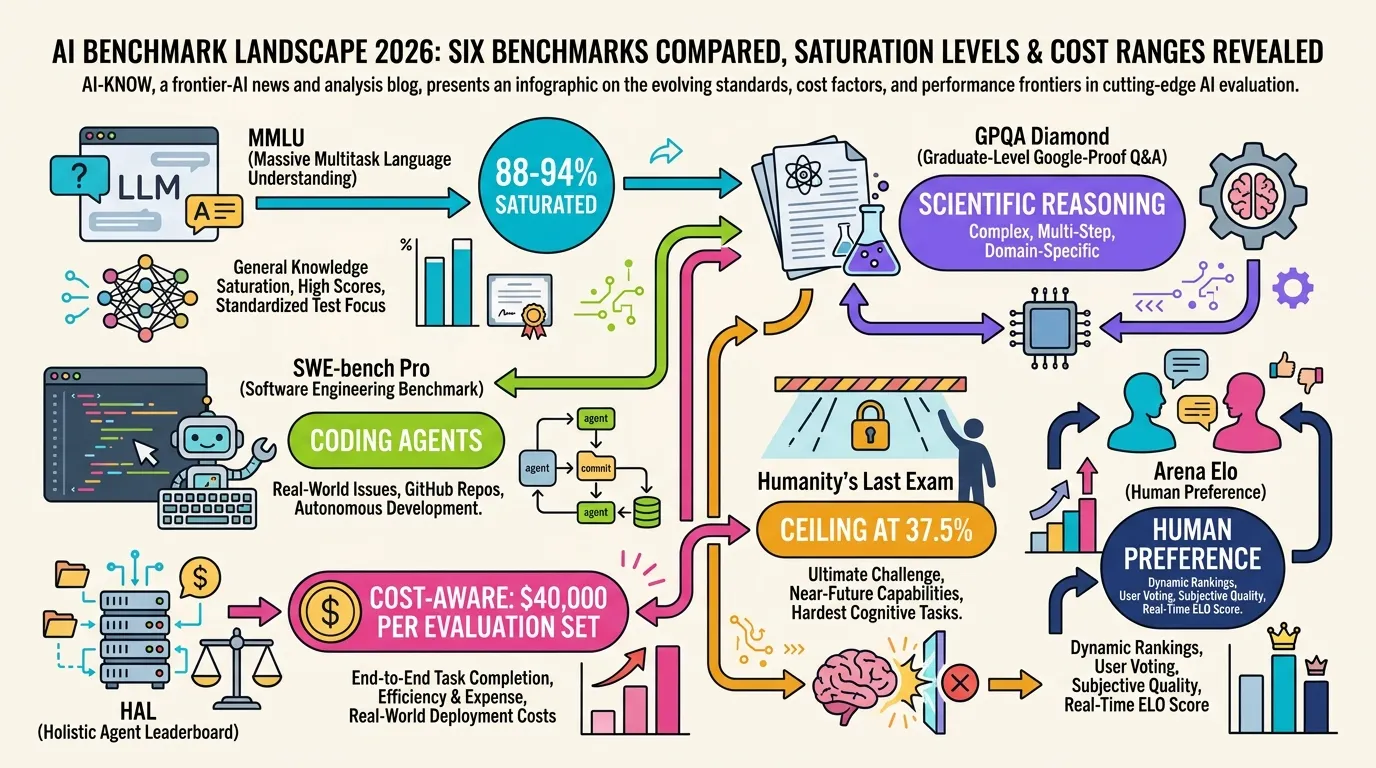
In 2026, AI evaluation has become the third resource bottleneck — after training compute and inference capacity. The Holistic Agent Leaderboard (HAL) spent approximately $40,000 to run 21,730 agent rollouts across 9 models and 9 benchmarks. More striking: a 9× cost difference produced just a 2-percentage-point accuracy gap between two approaches on the same task. Meanwhile, MMLU is saturated at 88–94% for frontier models, SWE-bench Verified is under data contamination pressure, and new benchmarks are proliferating faster than most teams can track. Choosing the right evaluation suite has become a business-critical decision, not a research afterthought.
Current Major Benchmarks
MMLU (General Knowledge, Multi-Subject)
With top frontier models scoring 88–94%, MMLU is effectively saturated as a differentiator. It can no longer distinguish among frontier models. It remains useful only as a minimum threshold — “below 85%? not in the top tier” — but score differences within the 88–94% range are statistically meaningless for procurement decisions. Use case: historical comparison and basic capability floor verification.
GPQA Diamond (Scientific Reasoning, Expert-Level)
Designed so that even human experts with internet access score around 60%. Still underpopulated at the frontier with a 60–94% spread. Claude Opus 4.7 scores 87.6%; Claude Mythos Preview reaches 94.6% on GPQA Diamond. The most reliable benchmark for scientific reasoning and domain-expert task selection, where AI is now outperforming credentialed human experts in specific subject areas.
SWE-bench Verified / SWE-bench Pro (Coding)
SWE-bench Verified has a documented data contamination issue — 59.4% of hard tasks show training data overlap — and OpenAI has stopped reporting Verified scores. SWE-bench Pro has emerged as the replacement: 1,865 multi-language tasks averaging 107 lines of code changes across 4.1 files, run with standardized tooling and a 250-turn limit. Claude Opus 4.7 scores 64.3% on SWE-bench Pro; Claude Mythos Preview scores 77.8%.
HAL — Holistic Agent Leaderboard
Built by Princeton PLI and accepted at ICLR 2026, HAL is the first cost-aware, third-party standardized platform for Agent Evaluation. It spans four domains (coding, web navigation, scientific research, customer service) and embeds cost tracking as a default metric. Key finding: Browser-Use with Claude Sonnet 4 achieved 40% accuracy at $1,577, while SeeAct with GPT-5 Medium hit 42% for $171 — a 9× cost difference for a 2-point accuracy gap. As of April 2026, the leaderboard covers 26,597 rollouts. The CLEAR framework found up to 50× cost variation between approaches achieving similar accuracy on the same agentic tasks.
Humanity’s Last Exam (HLE)
2,500 questions designed by domain experts at the frontier of academic knowledge. Best model score: 37.5%. Functions as an upper-bound indicator of current frontier capability — the only benchmark where the question is not “which model wins” but “how far are we from expert-level reasoning.”
Arena Elo (LMSYS Chatbot Arena)
Human pairwise preference ratings aggregated into Elo scores, side-stepping training-data contamination entirely. The only large-scale measure of actual human preference for model outputs in realistic conversation contexts.
Comparison Matrix
| Benchmark | Purpose | Saturation | Cost estimate | Best use case |
|---|---|---|---|---|
| MMLU | General knowledge | Saturated (88–94%) | Low | Legacy comparison only |
| GPQA Diamond | Scientific reasoning | Underpopulated (60–94%) | Medium | Domain-expert task selection |
| SWE-bench Pro | Coding agents | Underpopulated (39–78%) | Medium–High | Software engineering agent selection |
| HAL (agent) | Cost-aware agent eval | Underpopulated | High (~$40K/set) | Agent ROI and cost-performance |
| HLE | Hard reasoning ceiling | Underpopulated (0–38%) | Medium | Upper-bound capability verification |
| Arena Elo | Human preference | N/A (ongoing) | Low | Product selection, conversational quality |
Choosing the Right Benchmark
Procurement and ROI evaluation of agent products → HAL. The only platform that standardizes cost alongside accuracy. Exposes 50× cost variability for similar accuracy — critical for infrastructure budgeting and vendor justification.
Scientific, medical, or legal domain model selection → GPQA Diamond. Not yet saturated; top models now outperform human experts in specific subject areas, making score differences meaningful for high-stakes domain selection where wrong answers have real consequences.
Coding agent selection → SWE-bench Pro. Avoids Verified’s contamination issue; longer modification spans make it more representative of real engineering tasks. A 37% gap between lab benchmark scores and real-world deployment performance has been documented for enterprise agents — SWE-bench Pro’s design narrows that gap.
Real-world product evaluation → Arena Elo. Captures what users actually prefer when the benchmark leaderboard doesn’t match deployment outcomes. Use as the final sanity check after lab evaluation.
2026 Outlook
LLM Evaluation costs will get worse before they get better: as agent complexity grows, rollout counts increase, and evaluation infrastructure investment is scaling toward parity with research budgets. BenchLM.ai now tracks 226 models across 185 benchmarks, creating the need for meta-evaluation — frameworks to evaluate which benchmarks to use. The second half of 2026 will see Agent Evaluation standardization efforts accelerate around HAL, with NIST and ISO evaluation guideline development running in parallel. The era of “pick any benchmark and trust the number” is over.
Sources:
- HuggingFace: AI evals are becoming the new compute bottleneck
- HAL: Holistic Agent Leaderboard
- HAL Paper (arXiv 2510.11977)
- HAL GitHub harness
- Kili Technology: AI Benchmarks 2026 — Top Evaluations and Their Limits
- LLM Stats: Leaderboard 2026
- BenchLM: LLM Leaderboard 2026 — 226 Models, 185 Benchmarks
- SWE-bench Verified Leaderboard
- SWE-bench Pro Leaderboard
- Open-Weight LLM Rankings April 2026: MMLU Is Saturated, Here’s What to Use Instead
- SWE-bench Official Leaderboards
- Iternal AI: LLM Benchmarks 2026 — 30+ Models Ranked
- Vellum: LLM Leaderboard 2026
- LXT: LLM Benchmarks in 2026: What They Prove and What Your Business Needs
- AI Agent Benchmarks 2026: Performance, Accuracy & Cost Compared
- Berkeley: How We Broke Top AI Agent Benchmarks
- AI Benchmarks 2026 Comparison (aizolo)
- Stanford AI Index 2026: Technical Performance
- Mysummit: How LLM Benchmarks Work 2026
- Multi-dimensional Framework for Evaluating Enterprise Agentic AI (arXiv)
- AI Agent Benchmark Compendium — 50+ Benchmarks (GitHub)
- Rapid Claw: AI Agent Framework Scorecard 2026
- LLM Market Cap: AI Benchmarks 2026
- Artificial Analysis: Comparison of AI Models across Intelligence, Performance, and Price
- Digital Applied: AI Evaluation Metrics Reference Guide 2026
- Spheron: AI Agent Benchmarking Infrastructure on GPU Cloud
- Springer: From benchmarks to deployment — a comprehensive review of agentic AI evaluation
Related Articles
State of LLM Reasoning 2026: Comparing GPT-5.5, Gemini 3 Deep Think, and AlphaEvolve
AI Compute Infrastructure 2026: Anthropic's $50B Pledge, the xAI Colossus Deal, and Google-Broadcom's 8.5GW Bet

10 Charts That Explain AI in 2026: Progress, Adoption Gaps, and Backlash
Space-Based AI Infrastructure 2026: Comparing Google, SpaceX, Cowboy Space, and Blue Origin in the Race to Orbit
Edge Omni Models in 2026: Gemma 3n, Nemotron Nano Omni, and Granite 4.1 Compared