Multimodal LLMs Become Essential Infrastructure: Japan Adoption Trends and the Native Multimodal Shift in 2026
Gemini 3 and GPT-5 are the new baseline — here is how Japan is deploying multimodal AI across healthcare, retail, manufacturing, and automotive
“Multimodal AI” has crossed a threshold. It is no longer a differentiating feature — it is a baseline expectation. The 2026 Japanese market provides a particularly clear view of this transition, with domestic SIers and cloud vendors racing to publish implementation guides, while foundation model providers compete on context window size and native modality support.
This piece maps that landscape: which models are dominating, which verticals are absorbing the technology fastest, and what the architectural shift to native multimodal means for organizations still running “vision encoder + LLM” stacks.
The 2026 Baseline: Gemini 3 and GPT-5 as Defaults
In Japan’s enterprise AI conversations, two models appear as defaults across nearly every vendor’s documentation: Gemini 3 (Google DeepMind, 1M+ token context, cross-modal processing of text, image, audio, video, and code) and GPT-5 (OpenAI, unified text + image learning). Both have reached the market penetration threshold where domestic integrators assume them as the substrate rather than evaluating them as options.
The concentration reflects a broader global pattern: enterprise procurement follows reference architecture, and when reference architecture converges on two platforms, all differentiation moves to the application layer above them.
Industry Verticals: Four Sectors Driving Adoption
The Multimodal LLM use case map in Japan has crystallized around four verticals:
Healthcare: Medical Image Reading
Diagnostic imaging — radiology, pathology, ophthalmology — is the highest-velocity application. Hospital systems are piloting models that read CT, MRI, and fundoscopy images alongside patient history text, producing preliminary differential diagnosis reports for physician review. The regulatory pathway (Pharmaceutical and Medical Device Act classifications) remains the primary bottleneck, not model capability.
Retail: Visual Search and Inventory
E-commerce operators are deploying multimodal AI for product attribute extraction from supplier images, customer-facing visual search (photo-to-product matching), and automated quality checks on warehouse inventory images. The business case is straightforward: image-only and text-only systems both fail at this task; multimodal inference closes the gap at acceptable latency.
Manufacturing: Anomaly Detection
Factory floor cameras feeding multimodal models for real-time defect detection is now a standard architecture proposal from domestic SIers. The differentiation has shifted to latency optimization (edge inference vs. cloud round-trip) and model fine-tuning on proprietary defect catalogs.
Automotive: Sensor Fusion
Automotive OEMs and Tier-1 suppliers are exploring multimodal AI for sensor fusion tasks — combining camera, lidar, radar, and textual specification inputs into unified vehicle state representations. This is early-stage relative to other verticals, but the foundation model capabilities required have become available in 2025-2026.
The Architectural Shift: From “Vision Encoder + LLM” to Native Multimodal
The most significant technical development of 2025-2026 is not a new benchmark score — it is an architectural transition. Previous-generation multimodal systems bolted a vision encoder (e.g., a CLIP-style model) onto an existing LLM, creating a two-stage pipeline with alignment artifacts and modality-specific failure modes.
The 2026 generation is different. Models like Gemini 3, Llama 4, and GLM-4.6V are designed from training to be natively multimodal — modalities are not separated and recombined but are handled in a unified representational space. The practical implications:
- Cross-modal reasoning improves: the model can reason about relationships between image regions and text spans without explicit alignment steps
- Context window unification: a 1M-token context applies across modalities, not separately to text and image
- Latency reduction: eliminating the encoder + projection step reduces inference latency for mixed-modality inputs
For organizations already deployed on first-generation multimodal stacks, this creates a technical debt problem: the architecture assumptions baked into their pipelines no longer match the frontier.
Japan-Specific Dynamics: Domestic Model Competition
The global multimodal conversation is not the only story in Japan. Two emerging threads are worth tracking:
Government AI “Gennai”: Japan’s government-backed AI initiative is moving toward production, with early reports suggesting multimodal capability is a design requirement. If Gennai reaches enterprise procurement, it would represent the first significant alternative to US-origin models in sensitive-sector deployments.
Claude Mythos in Finance: Anthropic’s Claude Mythos model (financial institution adoption reported) suggests that the financial services vertical — historically risk-averse on AI — is beginning to commit to specific model partnerships for multimodal document processing: loan agreements, financial statements, and regulatory filings that combine text and structured image data.
Implications for Organizational AI Adoption
The multimodal baseline shift has concrete implications for AI adoption planning:
- Audit your existing vision pipelines: If you have production systems using first-generation vision encoder + LLM architectures, plan for migration in the 2026-2027 window as native multimodal models drive down the cost of replacement
- Vertical specialization beats general capability: In Japan’s market, the SIers gaining traction are those with industry-specific fine-tuning and compliance knowledge, not those with the largest base model
- Regulatory lead time: Healthcare and financial services verticals face the longest regulatory lead times; begin approval pathway mapping now if you intend to deploy in these sectors
Risks and Open Questions
- Model concentration risk: Over-reliance on two foundation model providers creates vendor dependency; monitor whether domestic models (Gennai, Claude Mythos) offer viable alternatives for sensitive data contexts
- Latency at scale: Native multimodal models with 1M+ token contexts carry significant inference costs; production economics require careful architecture planning
- Modality coverage gaps: “Multimodal” claims vary significantly — verify specific modality combinations (audio input, video understanding) against your use case before committing
Sources: マルチモーダルAIとは?仕組みや業界別活用事例を紹介 — FPT Software Japan (Feb 2026)
Related Articles
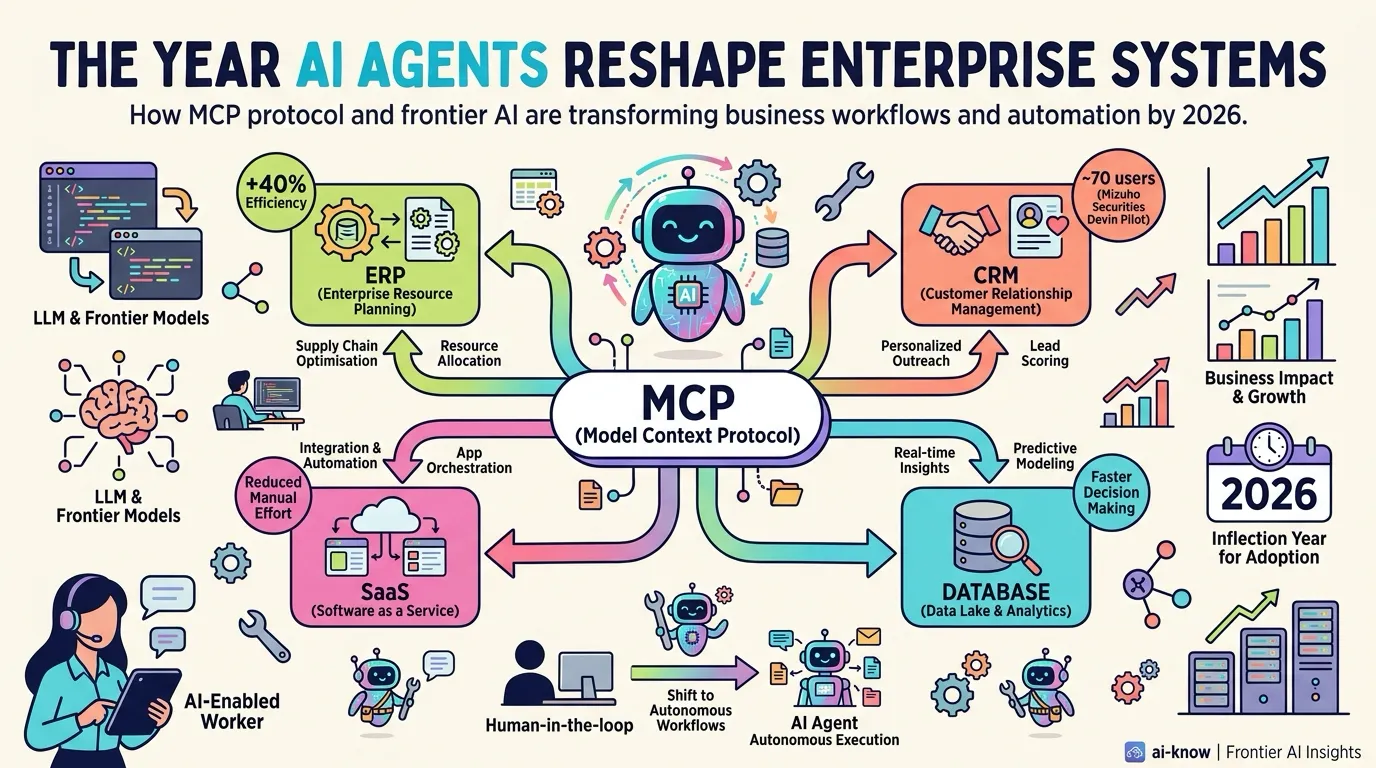
The Year AI Agents Reshape Enterprise Systems — MCP Becomes the Connectivity Standard
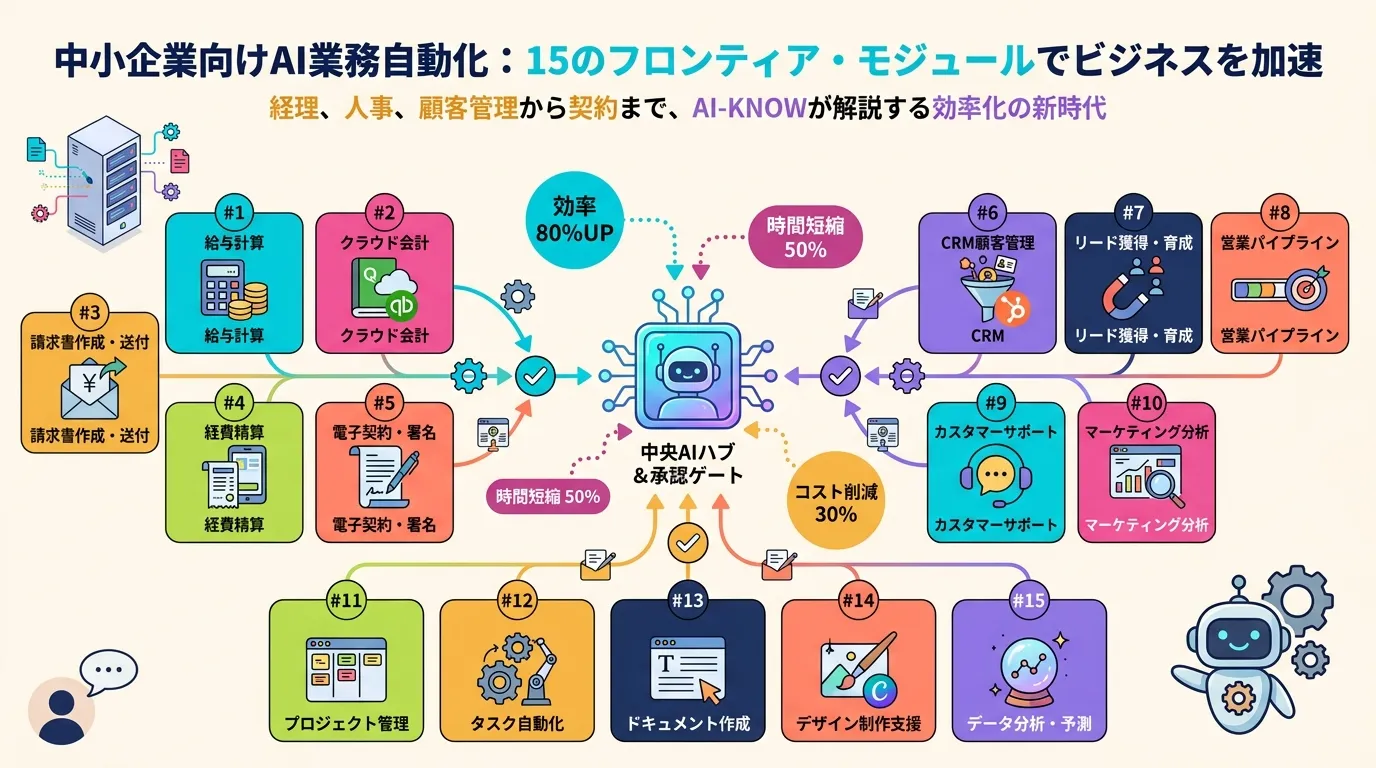
Anthropic Launches Claude for Small Business: 15 Agentic Workflows to Close the SMB AI Gap
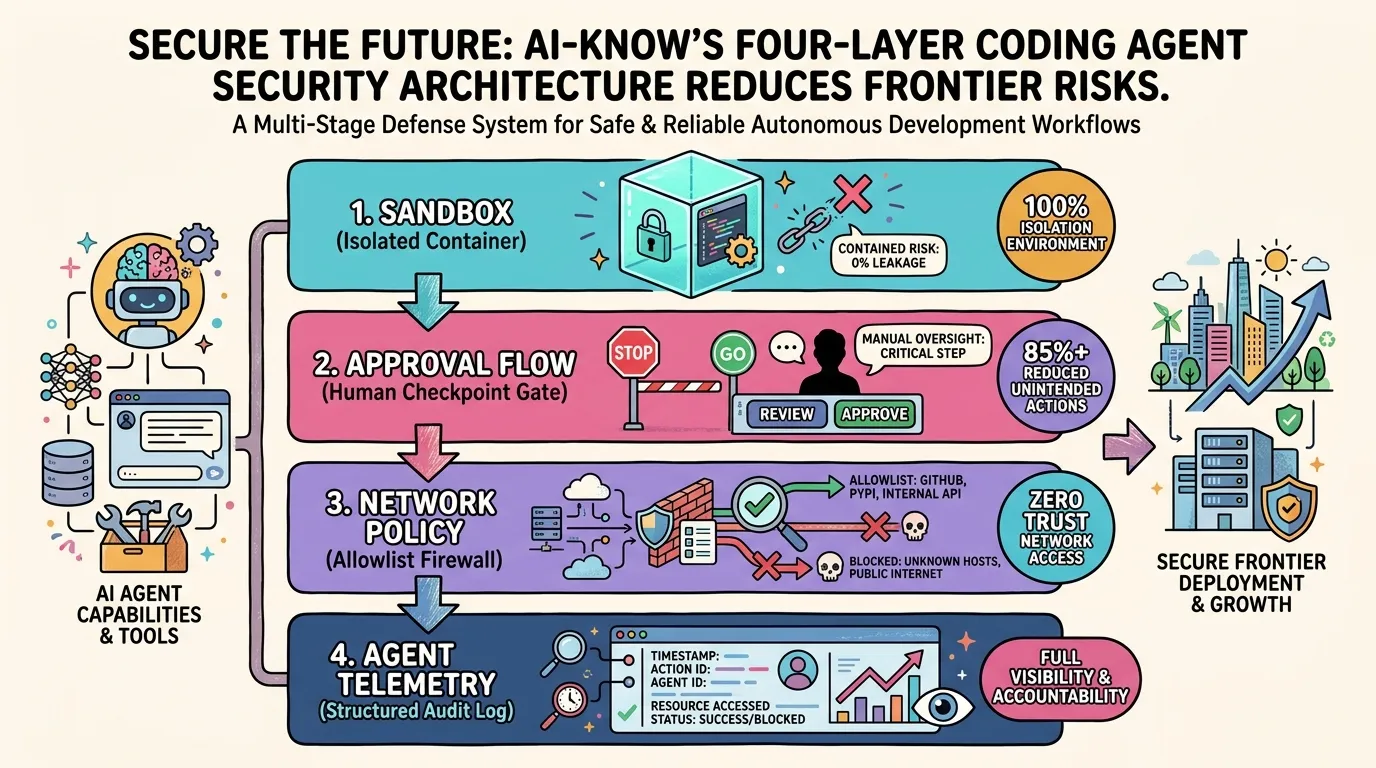
OpenAI's Four-Layer Defense for Codex — Engineering Safe Agentic Code Execution
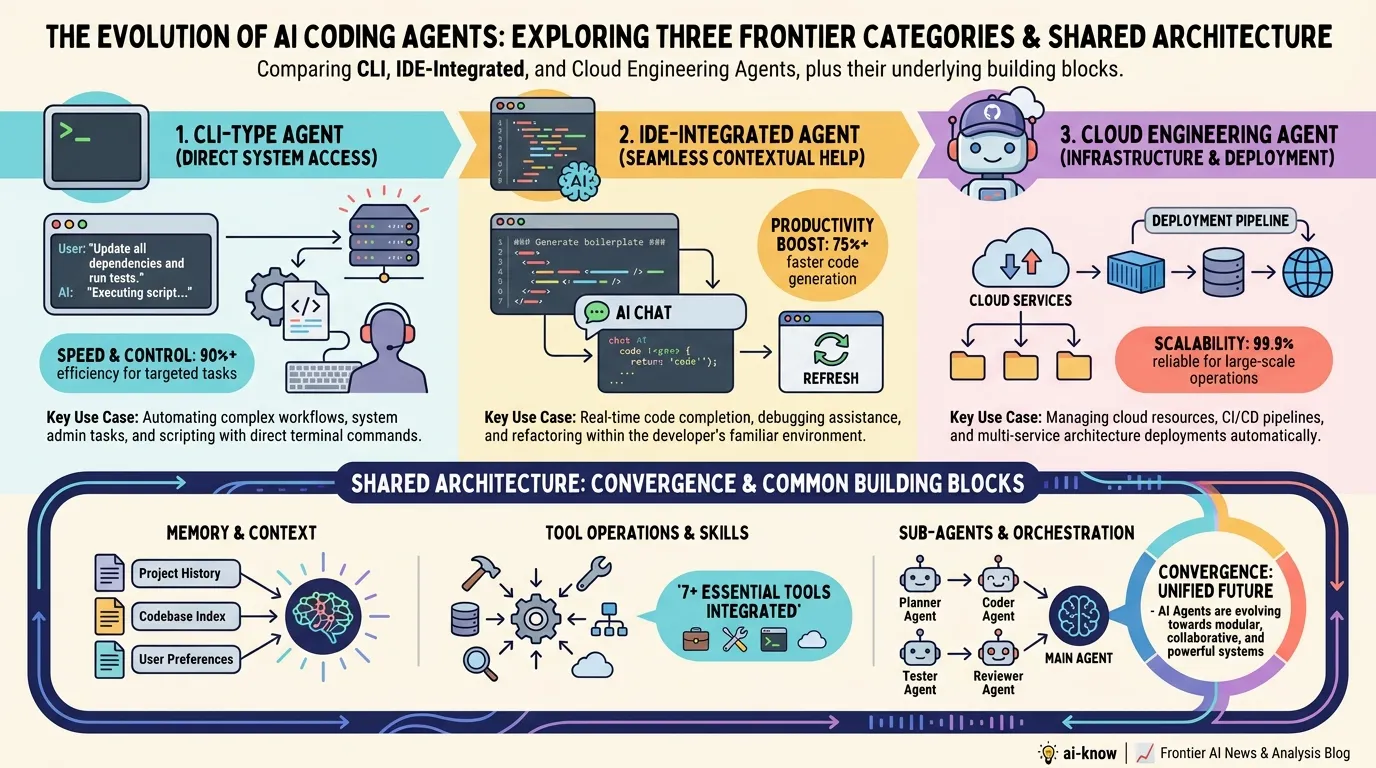
AI Agent Architecture in 2026: Four Essential Design Patterns for Production
How OpenAI Rebuilt Its WebRTC Stack from Scratch to Deliver Low-Latency Voice AI at Scale