AI 評価インフラの現在地 2026 — MMLU 飽和から HAL・SWE-bench Pro・HLE まで、ベンチマーク選択の実践ガイド
コスト 9 倍・精度差 2 ポイントという現実。急増するベンチマーク群から何を使えばいいかを整理する

2026 年 5 月、AI 評価インフラは静かに「第三のボトルネック」へと変貌した。学習用 GPU 確保・推論キャパシティに続き、今度は評価自体にかかるコストと複雑さが急拡大している。Holistic Agent Leaderboard(HAL)が 21,730 回のエージェントロールアウトを評価するために消費したコストは約 4 万ドル。同程度の精度(差 2 ポイント)を異なるフレームワークで達成した場合のコスト差は 9 倍に達した。MMLU が飽和し、SWE-bench Verified がデータ汚染疑惑で揺れ、新しいベンチマーク群が次々と登場するなか、どの尺度で何を測るかが企業の AI 調達判断を左右する意思決定になってきた。
現状の主要ベンチマーク / 選択肢
MMLU(基礎知識・多科目)
2026 年現在、トップフロンティアモデルは 88〜94% に達し、事実上飽和状態にある。モデル間の差を見分けるツールとしての機能を失いつつある。業界の暗黙の合意として「85% 未満はトップ層に入らない」が最低閾値として機能しているにすぎない。用途:過去性能との比較・下位互換性確認のみ。
GPQA Diamond(科学推論・専門家レベル)
博士レベルの科学問題で構成され、人間の専門家がインターネット付きで回答しても正解率が 60% 前後にとどまる難度。2026 年でもまだフロンティアを十分に分離できる(60〜94% のスプレッド)。Claude Opus 4.7 が 87.6%、Claude Mythos Preview が 94.6% を記録。科学的推論・専門文書審査の用途でのモデル選定に最も信頼できるベンチマーク。
SWE-bench Verified / SWE-bench Pro(コーディング)
SWE-bench Verified はデータ汚染問題(困難タスクの 59.4% でテスト問題がトレーニングデータと重複)で揺れており、OpenAI は Verified のスコア掲載を停止した。代替として SWE-bench Pro が台頭:1,865 タスク・平均 107 行のコード変更・4.1 ファイルにまたがるタスクを標準ツールで評価する。Claude Opus 4.7 は SWE-bench Pro で 64.3%(Claude Mythos Preview が 77.8%)。
HAL — Holistic Agent Leaderboard
Princeton PLI が構築・ICLR 2026 採択のエージェント評価専用インフラ。4 領域(コーディング・Web ナビゲーション・科学研究・カスタマーサービス)で並列評価し、コストを評価のデフォルト指標に組み込む唯一のプラットフォーム。代表的な発見:Browser-Use + Claude Sonnet 4 が $1,577 で 40% を達成した一方、SeeAct + GPT-5 Medium は $171 で 42%(コスト 9 倍、精度 -2%)。2026 年 4 月時点で 26,597 ロールアウトを収録。
Humanity’s Last Exam(HLE)
ドメイン専門家が設計した 2,500 問で構成。最良モデルでも正解率 37.5% という難度で、現時点のフロンティアの「天井」を示す上限指標として機能する。
Arena Elo(LMSYS Chatbot Arena)
実ユーザーが 2 モデルの回答を盲目的に比較して選ぶ方式で集計された Elo スコア。ラボベンチマークの汚染問題を迂回し、実際の人間の好みをキャプチャする唯一の大規模指標。
比較表
| ベンチマーク | 目的 | 飽和状況 | コスト目安 | 最適ユースケース |
|---|---|---|---|---|
| MMLU | 一般知識網羅 | 飽和(88–94%) | 低 | レガシー比較のみ |
| GPQA Diamond | 科学的推論最難関 | 未飽和(60–94%) | 中 | 専門知識タスクのモデル選定 |
| SWE-bench Pro | コーディングエージェント | 未飽和(39–78%) | 中〜高 | ソフト開発エージェント選定 |
| HAL(エージェント) | コスト込みエージェント評価 | 未飽和 | 高(〜$40,000/セット) | エージェント ROI・費用対効果評価 |
| HLE | 最難関推論上限 | 未飽和(0–38%) | 中 | 天井能力確認・研究用 |
| Arena Elo | 実ユーザー嗜好 | N/A(継続更新) | 低 | プロダクト選定・会話品質評価 |
使い分けの推奨
エージェント製品の調達・ROI 評価 → HAL。 コスト込みの評価が標準化された唯一のプラットフォーム。50 倍を超えるコスト差が精度 2 ポイント差以内で生じることを可視化でき、インフラ予算の根拠になる。
科学・医療・法律ドメインのモデル選定 → GPQA Diamond。 飽和していない最も信頼できる難度指標。人間専門家より AI が高スコアを取り始めている領域が出てきた事実が実務的な意思決定の根拠になる。
コーディングエージェント評価 → SWE-bench Pro。 Verified の汚染問題を回避し、より長い変更スパンを要求するため実務タスクへの相関が高い。企業エージェントではラボスコアと実世界の 37% ギャップが報告されており、Pro の設計がそれを縮小する。
プロダクトの実際のユーザー評価 → Arena Elo。 ラボベンチマーク高スコアが実際のユーザー満足度に直結しない問題を補完する唯一の指標。プロダクト選定の最終判断軸として有効。
2026 年の見通し
LLM 評価 コストの問題は解決より先に悪化する見込みだ。エージェントの複雑さが増すほどロールアウト数が増え、評価インフラへの投資は研究費と並ぶ規模になりつつある。BenchLM.ai が 226 モデルを 185 ベンチマークで追跡しており、どのベンチマークを使うかを判断する「メタ評価」の必要性が生まれている。2026 年後半は エージェント評価 の標準化に向けた動きが HAL を中心に加速し、NIST や ISO の評価ガイドライン整備とも連動していく見通しだ。
参考:
- HuggingFace: AI evals are becoming the new compute bottleneck
- HAL: Holistic Agent Leaderboard
- HAL Paper (arXiv 2510.11977)
- HAL: GitHub harness
- Kili Technology: AI Benchmarks 2026 — Top Evaluations and Their Limits
- LLM Stats Leaderboard 2026
- BenchLM: LLM Leaderboard 2026
- SWE-bench Verified Leaderboard
- SWE-bench Pro Leaderboard
- Open-Weight LLM Rankings April 2026: MMLU Is Saturated, Here’s What to Use Instead
- SWE-bench Official Leaderboards
- Iternal AI: LLM Benchmarks 2026 — 30+ Models Ranked
- Vellum: LLM Leaderboard 2026
- LXT: LLM Benchmarks in 2026
- AI Agent Benchmarks 2026: Performance, Accuracy & Cost
- Berkeley: How We Broke Top AI Agent Benchmarks
- AI Benchmarks 2026 Comparison
- Stanford AI Index 2026: Technical Performance
- Mysummit: How LLM Benchmarks Work 2026
- Multi-dimensional Framework for Evaluating Enterprise Agentic AI (arXiv)
- AI Agent Benchmark Compendium — 50+ Benchmarks (GitHub)
- Rapid Claw: AI Agent Framework Scorecard 2026
- LLM Market Cap: AI Benchmarks 2026
- Zenn: LLMベンチマーク21選を完全解説
- BrainPad: 生成 AI 評価指標とベンチマークの解説
- Digital Applied: AI Evaluation Metrics Reference Guide 2026
- Artificial Analysis: Comparison of AI Models across Performance and Price
- Spheron: AI Agent Benchmarking Infrastructure on GPU Cloud
関連記事
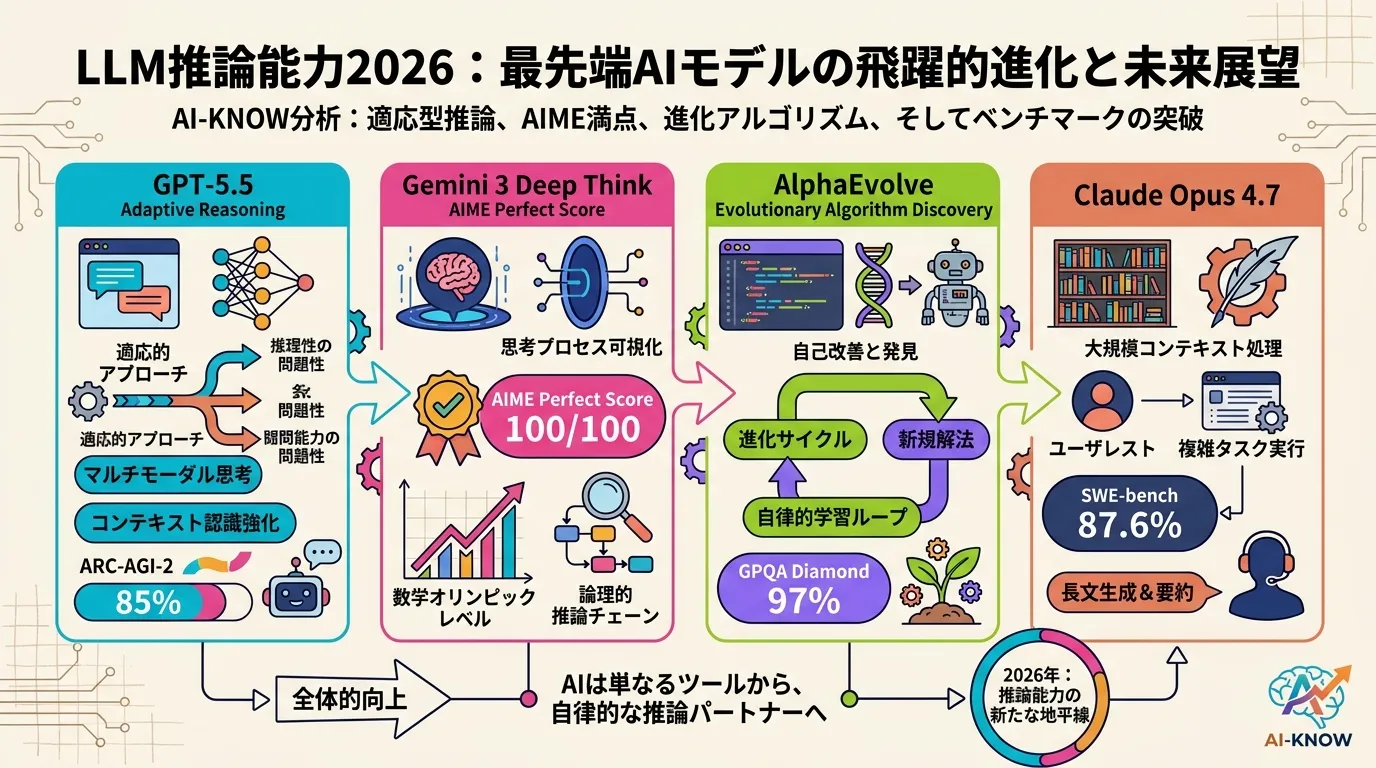
LLM 推論能力の現在地 2026 — GPT-5.5 / Gemini 3 Deep Think / AlphaEvolve を比べる
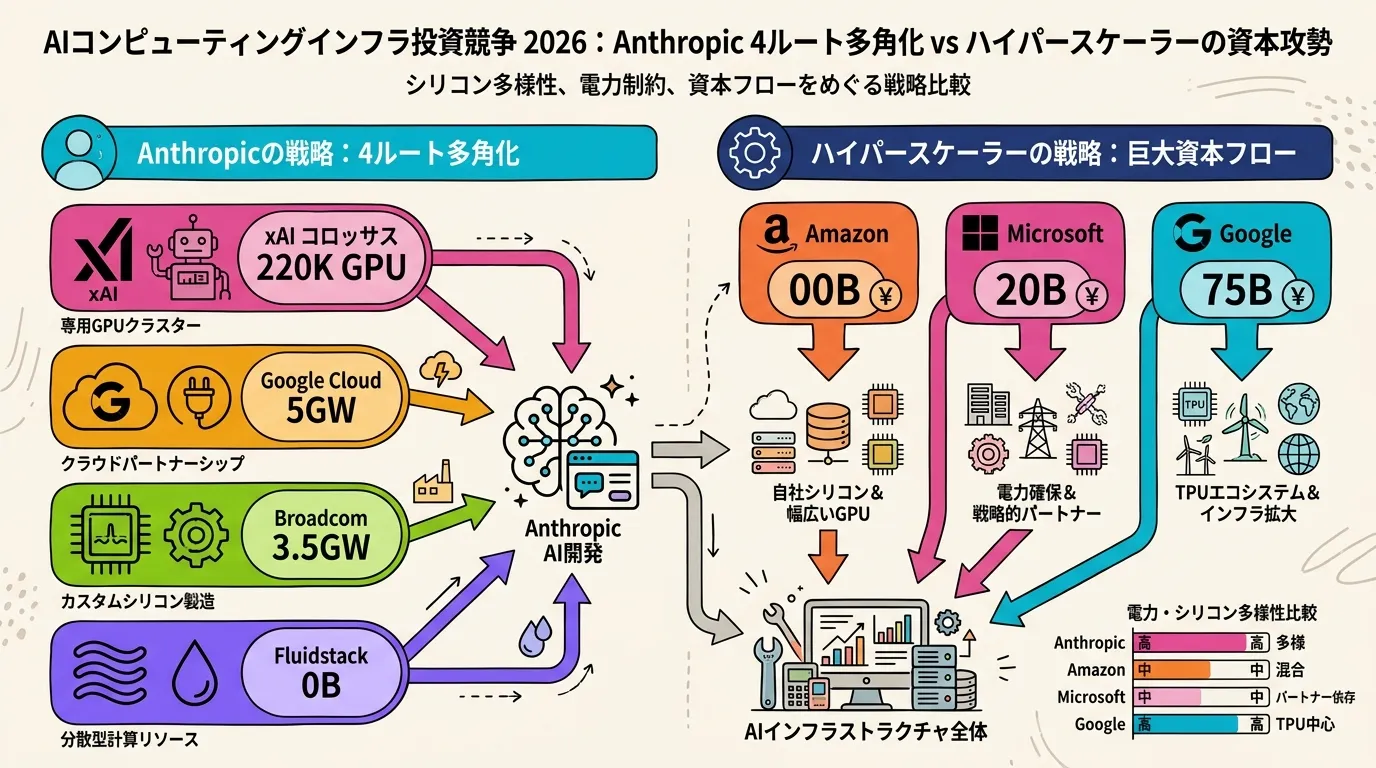
AI 計算インフラ投資の現在地 2026 — Anthropic 500 億ドル / xAI Colossus / Google-Broadcom を比較する
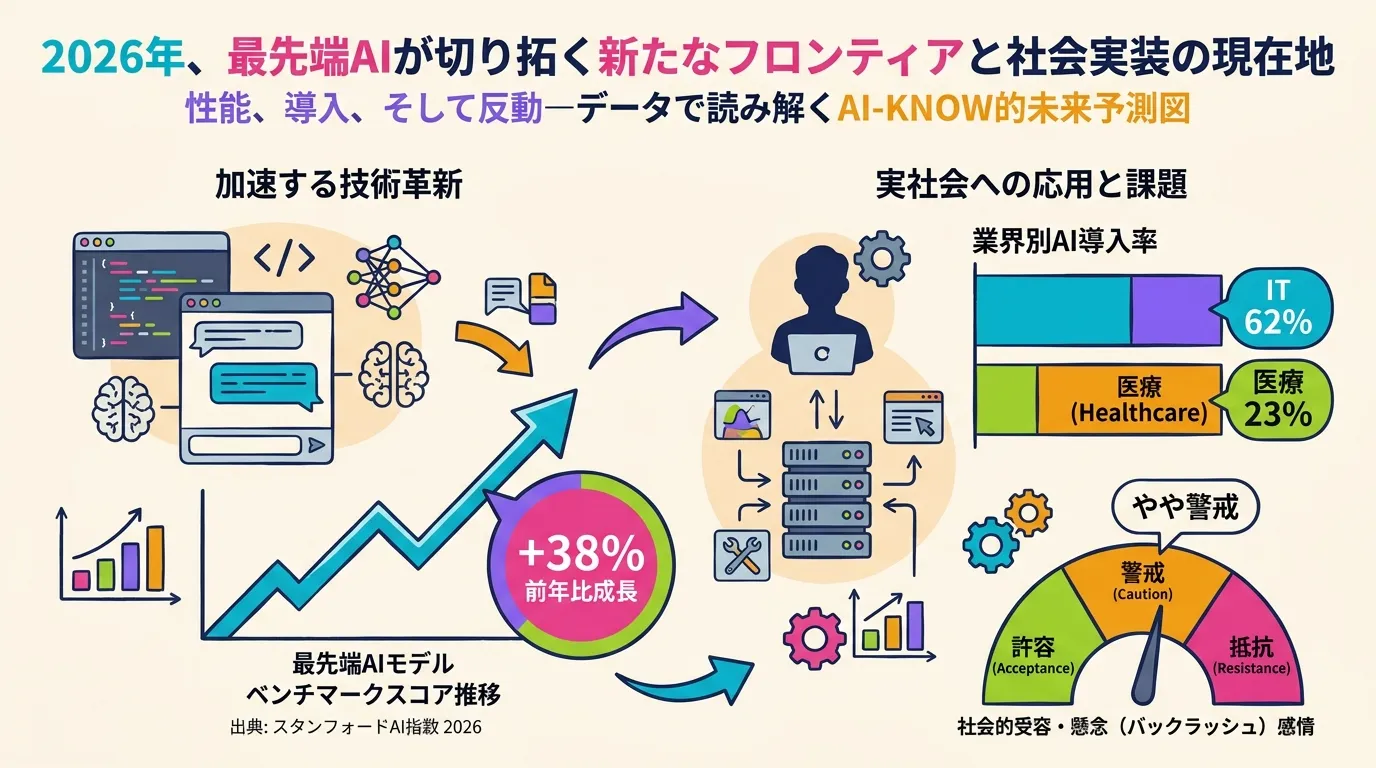
AI の現在地を読む 10 枚のグラフ — Stanford AI Index 2026 × MIT TR が照らす進化と格差
宇宙 AI インフラ 2026 — Google・SpaceX・Cowboy Space・Blue Origin の軌道上計算レース比較
エッジ向けオムニモデルの現在地 2026 — Gemma 3n / Nemotron Nano Omni / Granite 4.1 を用途別に比較する