オープンソース LLM 2026 年春の現在地 — DeepSeek V4 / Gemma 4 / Qwen 3.5 / Llama 4 比較
MIT・Apache 2.0 で frontier 級の性能が手に入る時代。8 モデルを「コーディング・推論・長文脈・ハードウェア要件」の軸で整理する
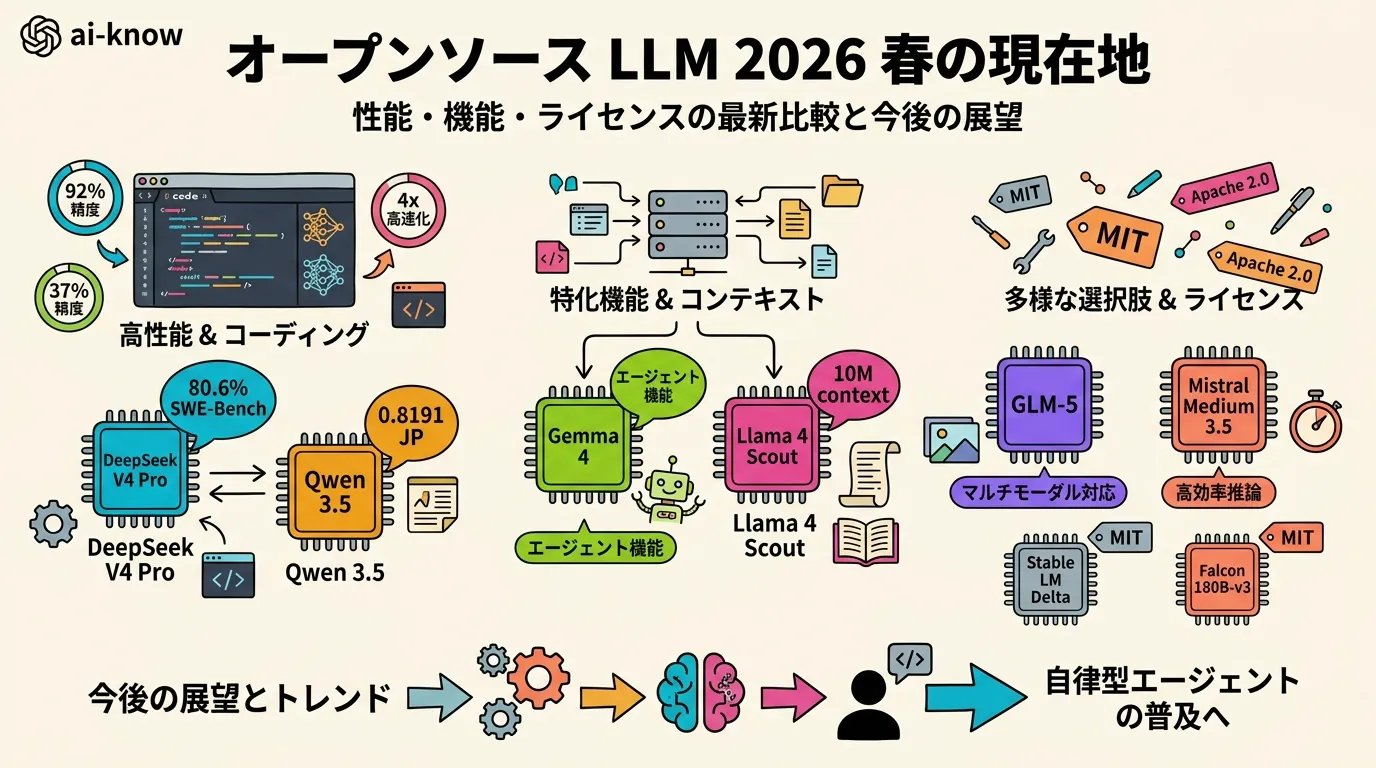
2 年前まで、オープンソース LLM の議論は Llama 一強だった。2026 年春の景色は様変わりしている。DeepSeek V4 Pro が SWE-Bench Verified で 80.6% を出し、Claude Opus 4.6 とほぼ同水準。Gemma 4 は Apache 2.0 ライセンスで agentic ワークフロー特化、Alibaba の Qwen 3.5 が日本語性能で初めて 0.80 の壁を超えた。
closed-source vs open-source の構図は、もはや単純な性能差では語れない。本稿では 2026 年 4〜5 月時点の主要 オープンソース LLM 8 モデルを、用途別の選択指針として整理する。
主要プレイヤー(2026 年 4〜5 月)
| モデル | ベンダー | アーキテクチャ | ライセンス | 注目点 |
|---|---|---|---|---|
| DeepSeek V4 Pro | DeepSeek | MoE 1.6T (49B activated) | MIT | SWE-Bench 80.6%、1M context、$0.30/MTok |
| DeepSeek V4 Flash | DeepSeek | MoE 284B (13B activated) | MIT | 軽量版、同 1M context |
| Gemma 4 31B Dense | Google DeepMind | Dense | Apache 2.0 | Arena 第 3 位、τ2-bench 86.4%、256K context |
| Gemma 4 26B MoE | Google DeepMind | MoE | Apache 2.0 | エッジ実行向け、agentic 特化 |
| Qwen 3.5 397B | Alibaba | MoE (A17B activated) | Apache 2.0 | 日本語 0.8191 でオープン勢初の 0.80 突破 |
| Llama 4 Scout | Meta | Dense | Llama Community | 10M token context が独走 |
| GLM-5 (Reasoning) | Zhipu AI | Dense | MIT | コーディングで GLM-4.7 が HumanEval 94.2% |
| Mistral Medium 3.5 | Mistral | Dense 128B | Apache 2.0 | SWE-Bench 77.6%、欧州系の安定供給 |
ライセンスは全モデル商用利用可。MIT / Apache 2.0 の純度の高さが企業導入の障壁を実質ゼロにしている。
用途別の選択指針
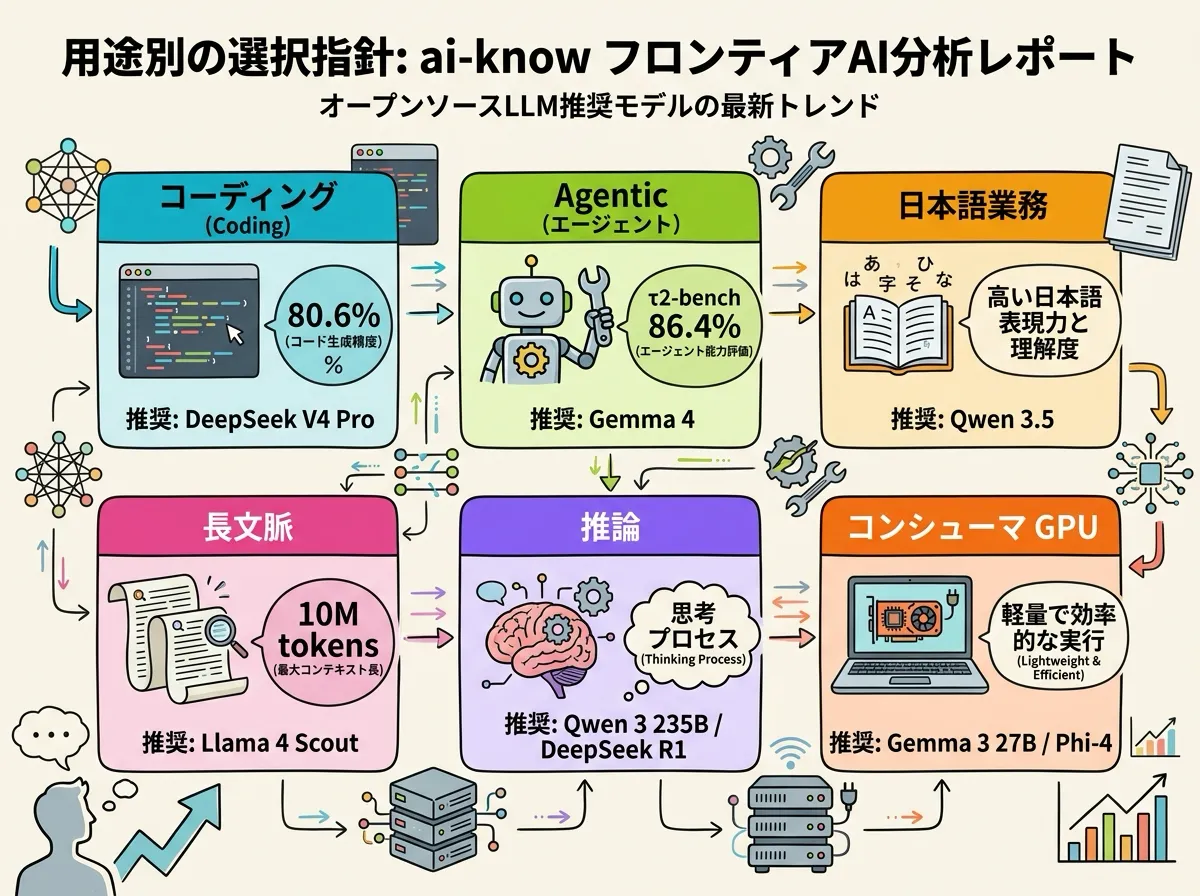
コーディング・エージェント
DeepSeek V4 Pro が現状の頂点。SWE-Bench Verified 80.6% は Claude Opus 4.6 と 0.2 ポイント差。Terminal-Bench 2.0 / LiveCodeBench でも Claude を逆転している。コーディングエージェント基盤を オンプレ + オープンウェイトで組みたいケースの第一選択。次点は GLM-5 Reasoning(HumanEval 94.2%)。
推論(Reasoning)
Mixture of Experts (MoE) の活用が鍵。**Qwen 3 235B(Reasoning モード)**または DeepSeek R1 が定番。GLM-5 Reasoning も伸びてきており、3 強構造になりつつある。
超長文脈
Llama 4 Scout の 10M token は独走。次点が DeepSeek V4 Pro / Flash の 1M。法務文書一式・コードベース全体・複数論文同時投入のような「100 万トークンを超える」ユースケースは Llama 4 Scout 一択。
Agentic ワークフロー(ツール実行 / 自動化)
Gemma 4 が「edge agentic」として設計された数少ないモデル。τ2-bench 86.4% は実運用での安定したツール呼び出しを意味する。Android 標準搭載という流通力もあり、モバイル / オフライン エージェント向けに有利。
コンシューマハードウェア(GPU 24GB 以下)
Gemma 3 27B か Phi-4 14B。GLM-4.7-Flash(30B、24GB VRAM 動作)も選択肢に入る。MoE モデルはアクティブパラメータが少なくても 総 VRAM 要件が高いので、Dense モデルが扱いやすい。
日本語業務利用
Qwen 3.5 397B が日本語ベンチマーク 0.8191 でトップ。次点は Qwen3 32B(コスト / 性能比で実用解)。日本語向けの fine-tuning が効きやすく、要約・翻訳・ビジネス文書生成で実用域。
業界構造の変化
オープンソースの主役が 米 Meta 一強 → 中国系 + Google + Mistral の多極化 に明確にシフトした。BenchLM.ai のオープンウェイト LB 上位の半数以上を中国ラボ(DeepSeek / Moonshot AI / Zhipu AI / Alibaba)が占める。Google は Gemma 4 で agentic edge という軸を切り、Mistral は欧州供給の安定性で差別化する。
フロンティアモデル の研究投資が closed → open へ流れているのは、収益化の難しさよりも ベンダーロックインを警戒する企業需要が大きい。MIT / Apache 2.0 ライセンスは「自社推論・自社ファインチューン」を可能にする決定打となる。
2026 年後半の見通し
- コーディング: GLM-5 / DeepSeek V4 / Qwen 3.5 の競争が続く。closed-source(Claude / GPT)との性能差は SWE-Bench で 1 ポイント以内に収束しつつある
- 長文脈: 10M token(Llama 4 Scout)の壁を Qwen / DeepSeek が破れるかが論点
- Agentic: τ2-bench / GAIA で 90% を超えるオープンモデルが年内に登場する見込み
- ライセンス: Llama Community License は Apache 2.0 / MIT に劣る。Llama 5 で再緩和が来るかが業界注目点
オープンソース LLM は「商用代替」のフェーズを終え、**「特定軸ではフロンティア」**になった。2026 年は「どれを選ぶか」よりも「何種類使い分けるか」が問われる年になる。
参考:Best Open-Source LLM in May 2026 (Codersera, 2026)、Open Source LLM Leaderboard 2026 (Vellum AI)、Best Open Source LLM in 2026 — Rankings & Benchmarks (BenchLM.ai)、DeepSeek V4 Complete Guide (Codersera, 2026)、CAISI Evaluation of DeepSeek V4 Pro (NIST, 2026)、Gemma 4 — Byte for byte, the most capable open models (Google Blog, 2026)、Gemma 4 — Google DeepMind、Open-Source LLM 2026 比較 (DevelopersIO)、日本語対応 LLM ランキング 2026 (Qualiteg)
関連記事
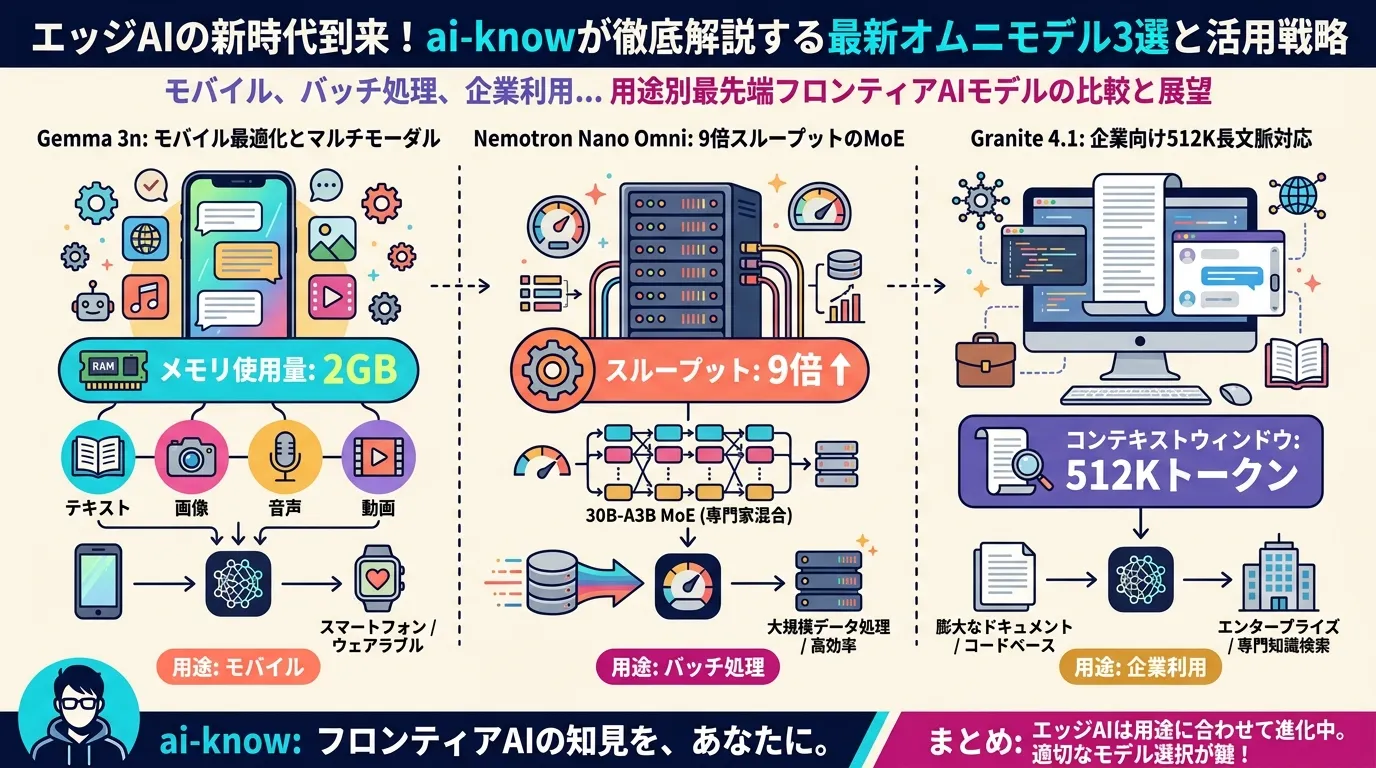
エッジ向けオムニモデルの現在地 2026 — Gemma 3n / Nemotron Nano Omni / Granite 4.1 を用途別に比較する
AI 計算インフラ投資の現在地 2026 — Anthropic 500 億ドル / xAI Colossus / Google-Broadcom を比較する
LLM 推論能力の現在地 2026 — GPT-5.5 / Gemini 3 Deep Think / AlphaEvolve を比べる

AI 評価インフラの現在地 2026 — MMLU 飽和から HAL・SWE-bench Pro・HLE まで、ベンチマーク選択の実践ガイド
宇宙 AI インフラ 2026 — Google・SpaceX・Cowboy Space・Blue Origin の軌道上計算レース比較