State of Open-Source LLMs in Spring 2026 — DeepSeek V4 / Gemma 4 / Qwen 3.5 / Llama 4 Compared
Frontier-grade performance is now available under MIT and Apache 2.0. We organize 8 open-weight models by use case: coding, reasoning, long context, hardware footprint.
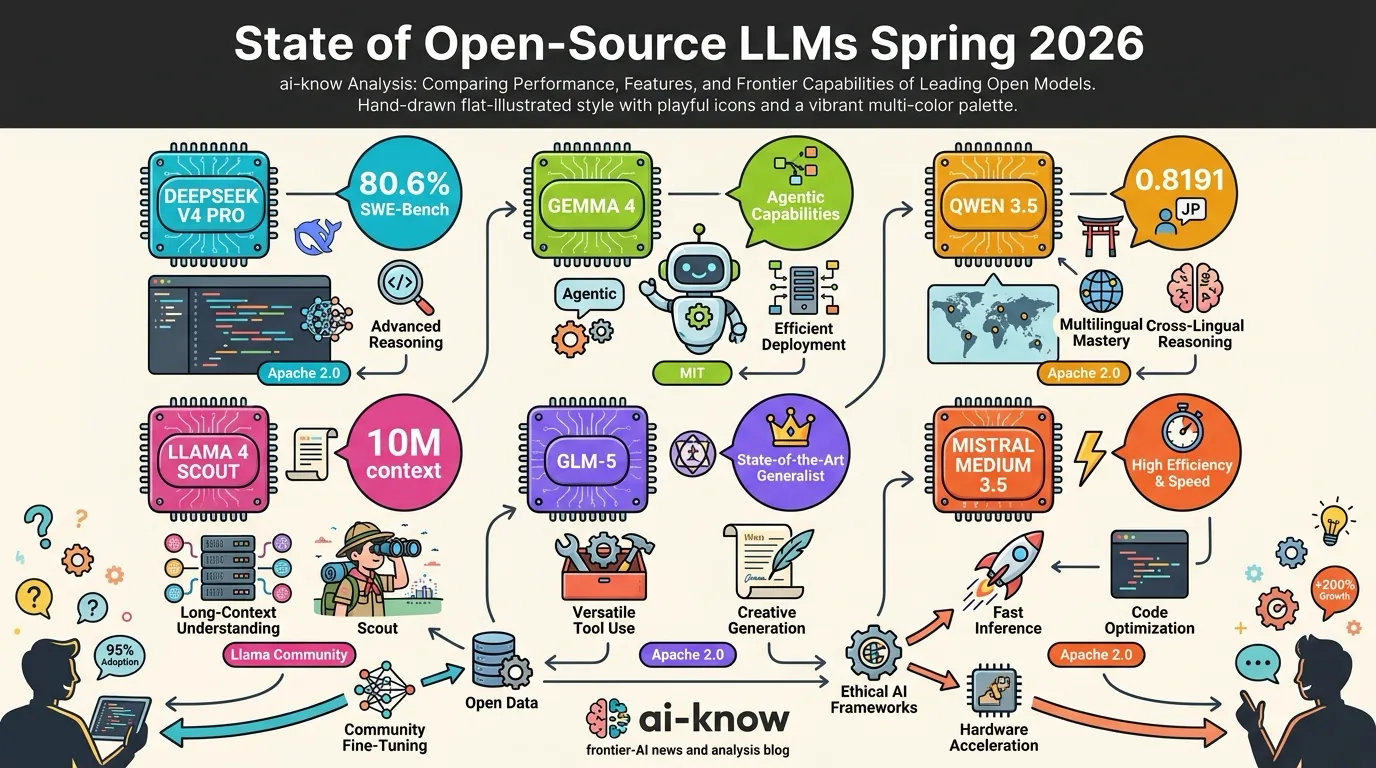
Two years ago, the open-source LLM conversation was dominated by Llama. The spring 2026 picture looks very different. DeepSeek V4 Pro hits 80.6% on SWE-Bench Verified — within 0.2 points of Claude Opus 4.6. Gemma 4 ships under Apache 2.0 with a deliberate focus on agentic workflows. Alibaba’s Qwen 3.5 became the first open-weight model to break the 0.80 barrier on Japanese-language benchmarks.
The closed vs. open framing no longer hinges on a simple performance gap. This piece organizes eight major Open-Source LLM models from April–May 2026 into a use-case-driven decision matrix.
The Players (April–May 2026)
| Model | Vendor | Architecture | License | Highlights |
|---|---|---|---|---|
| DeepSeek V4 Pro | DeepSeek | MoE 1.6T (49B activated) | MIT | SWE-Bench 80.6%, 1M context, $0.30/MTok |
| DeepSeek V4 Flash | DeepSeek | MoE 284B (13B activated) | MIT | Lighter sibling, same 1M context |
| Gemma 4 31B Dense | Google DeepMind | Dense | Apache 2.0 | Arena #3, τ2-bench 86.4%, 256K context |
| Gemma 4 26B MoE | Google DeepMind | MoE | Apache 2.0 | Edge-focused, agentic-native |
| Qwen 3.5 397B | Alibaba | MoE (A17B activated) | Apache 2.0 | First open-weight to break Japanese 0.80 |
| Llama 4 Scout | Meta | Dense | Llama Community | 10M token context — uncontested |
| GLM-5 (Reasoning) | Zhipu AI | Dense | MIT | GLM-4.7 hits HumanEval 94.2% |
| Mistral Medium 3.5 | Mistral | Dense 128B | Apache 2.0 | SWE-Bench 77.6%, European supply chain |
All listed models are commercially usable. The combination of MIT and Apache 2.0 has effectively removed enterprise licensing as a barrier.
Picking by Use Case
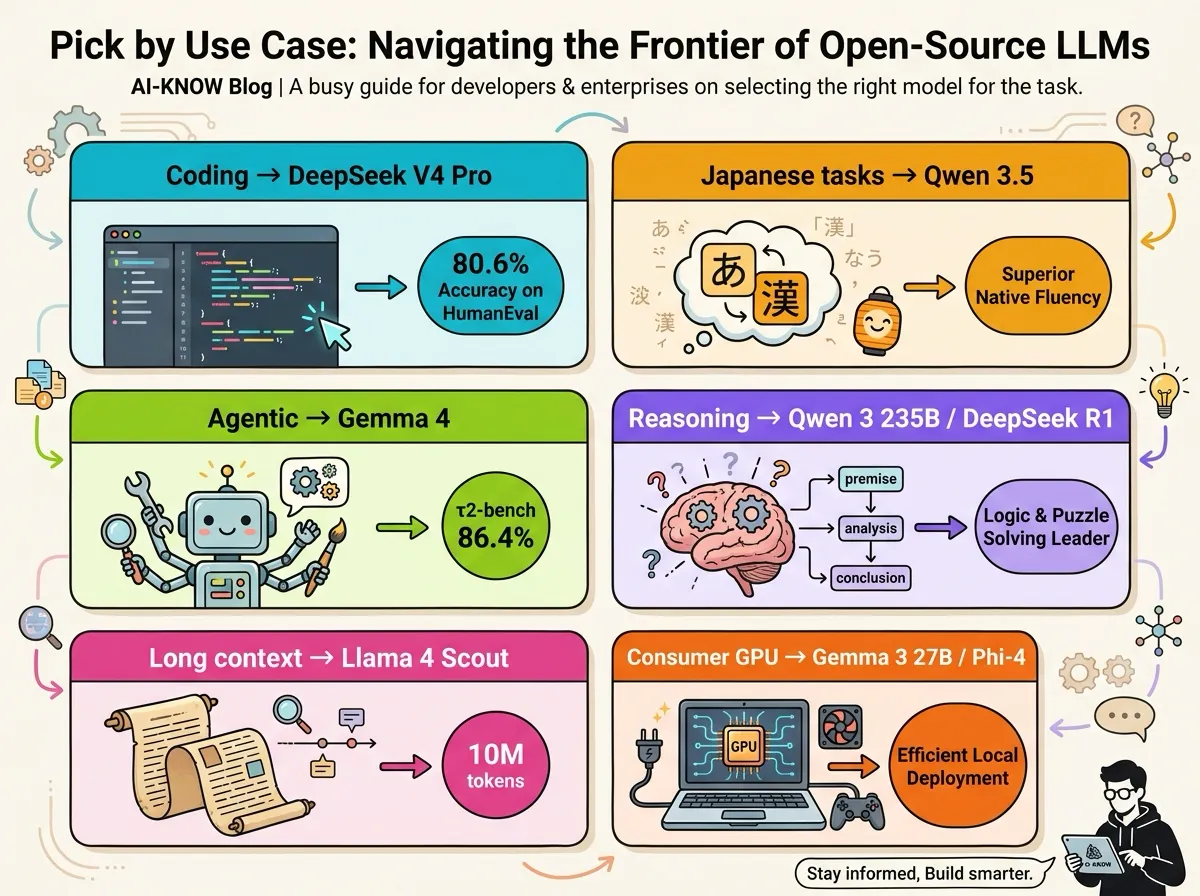
Coding & Agentic Engineering
DeepSeek V4 Pro sits at the top right now. Its 80.6% on SWE-Bench Verified trails Claude Opus 4.6 by only 0.2 points, and it leads Claude on Terminal-Bench 2.0 and LiveCodeBench. If you’re building a coding-agent stack on on-prem + open weights, this is the first pick. GLM-5 Reasoning (HumanEval 94.2%) is a strong second.
Reasoning
Mixture of Experts (MoE) usage is the key axis. Qwen 3 235B (Reasoning mode) or DeepSeek R1 are the standard picks. GLM-5 Reasoning is rising fast, making it a three-horse race.
Ultra-Long Context
Llama 4 Scout’s 10M-token window has no real peer. DeepSeek V4 Pro / Flash come next at 1M. For workloads beyond a million tokens — full legal corpora, entire codebases, multi-paper synthesis — Llama 4 Scout is the only option.
Agentic Workflows (Tool Use, Automation)
Gemma 4 is one of the few models explicitly designed for “edge agentic” deployment. Its τ2-bench score of 86.4% reflects stable real-world tool calling. Combined with native Android distribution, it’s well-positioned for mobile and offline agents.
Consumer Hardware (≤24GB GPU)
Gemma 3 27B or Phi-4 14B remain the safe picks. GLM-4.7-Flash (30B, runs on 24GB VRAM) is also viable. MoE models, while parameter-efficient at inference, still demand high total VRAM, so dense architectures are easier to fit.
Japanese Business Use
Qwen 3.5 397B tops Japanese benchmarks at 0.8191. Qwen3 32B is the practical cost/performance pick. Both fine-tune well for Japanese summarization, translation, and document generation.
The Industry Shift
Open-source leadership has clearly shifted from Meta-dominated to a multi-polar landscape spanning Chinese labs, Google, and Mistral. More than half of BenchLM.ai’s open-weight leaderboard top tier is occupied by Chinese labs (DeepSeek / Moonshot AI / Zhipu AI / Alibaba). Google has carved out the agentic-edge axis with Gemma 4. Mistral differentiates on European supply-chain reliability.
Investment in Frontier Models is flowing into open weights — driven less by monetization difficulty than by enterprise demand to avoid vendor lock-in. MIT and Apache 2.0 licenses are the decisive factor that makes “self-host inference, self-fine-tune” feasible.
What to Watch in Late 2026
- Coding: Continued tight competition among GLM-5 / DeepSeek V4 / Qwen 3.5. The gap to closed-source (Claude / GPT) on SWE-Bench is converging to within one point.
- Long context: Whether Qwen or DeepSeek can break Llama 4 Scout’s 10M-token wall.
- Agentic: Expect open models clearing 90% on τ2-bench / GAIA before year-end.
- Licensing: The Llama Community License lags MIT / Apache 2.0. Whether Meta loosens further with Llama 5 is a closely watched signal.
Open-source LLMs have moved past the “commercial alternative” phase. On specific axes, they are the frontier. 2026 is less about “which one to pick” and more about “how many to combine” inside a production stack.
Sources: Best Open-Source LLM in May 2026 (Codersera, 2026); Open Source LLM Leaderboard 2026 (Vellum AI); Best Open Source LLM 2026 — Rankings & Benchmarks (BenchLM.ai); DeepSeek V4 Complete Guide (Codersera, 2026); CAISI Evaluation of DeepSeek V4 Pro (NIST, 2026); Gemma 4 — Byte for byte, the most capable open models (Google Blog, 2026); Gemma 4 — Google DeepMind
Related Articles
Edge Omni Models in 2026: Gemma 3n, Nemotron Nano Omni, and Granite 4.1 Compared
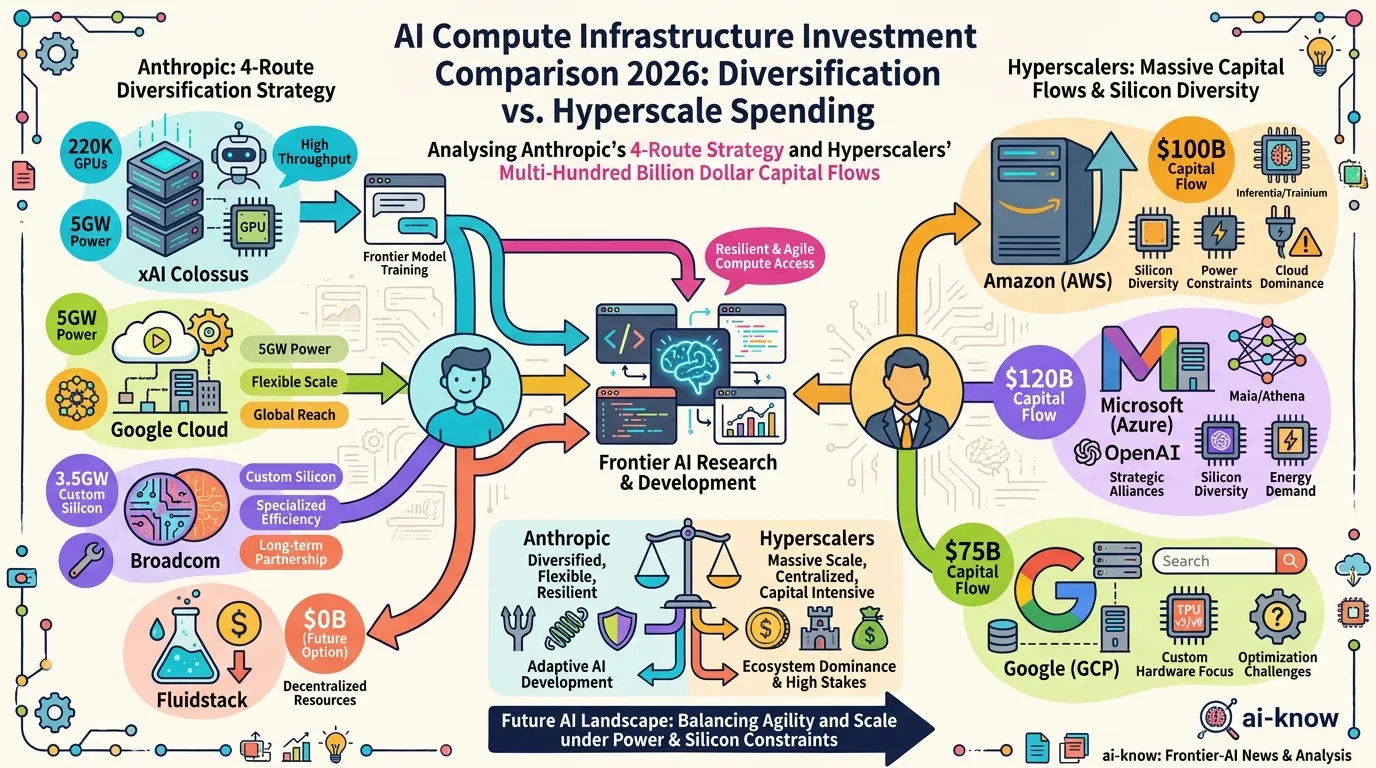
AI Compute Infrastructure 2026: Anthropic's $50B Pledge, the xAI Colossus Deal, and Google-Broadcom's 8.5GW Bet
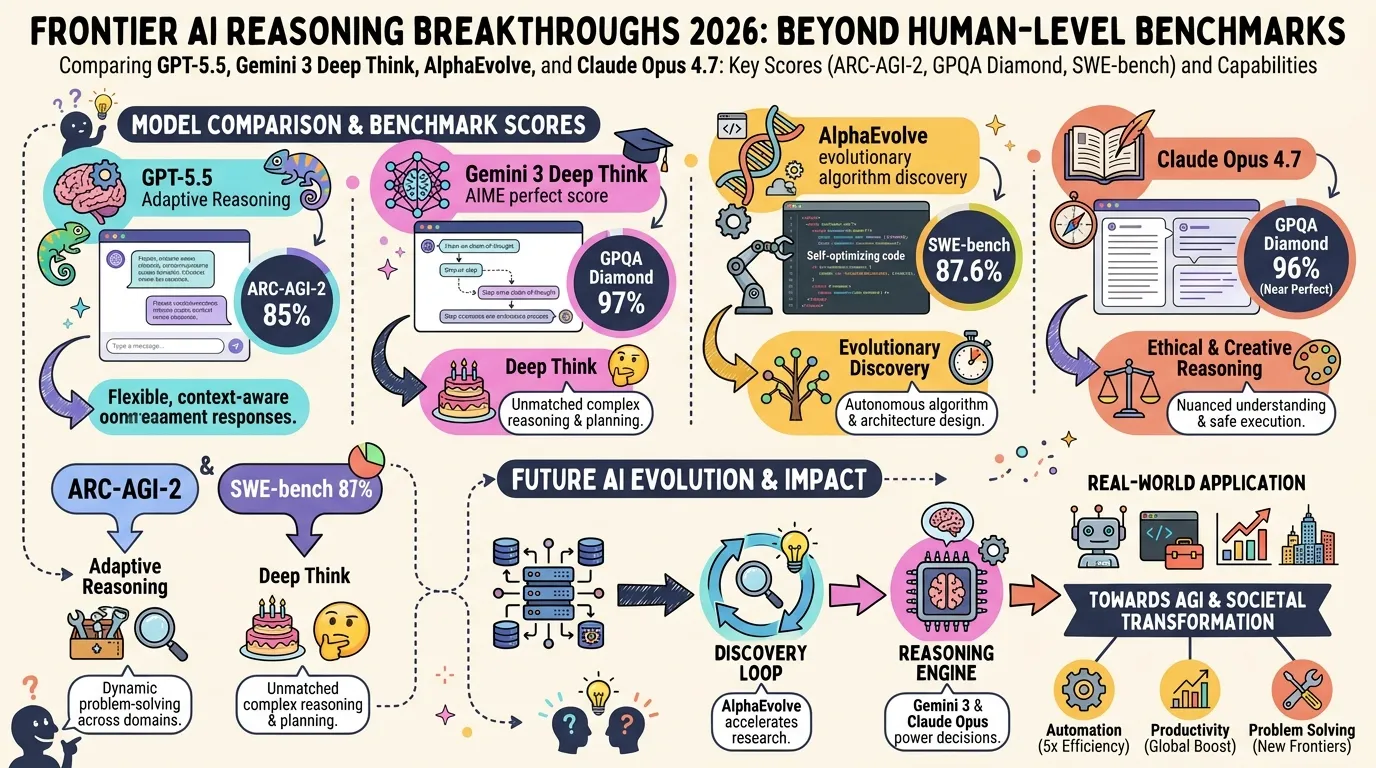
State of LLM Reasoning 2026: Comparing GPT-5.5, Gemini 3 Deep Think, and AlphaEvolve
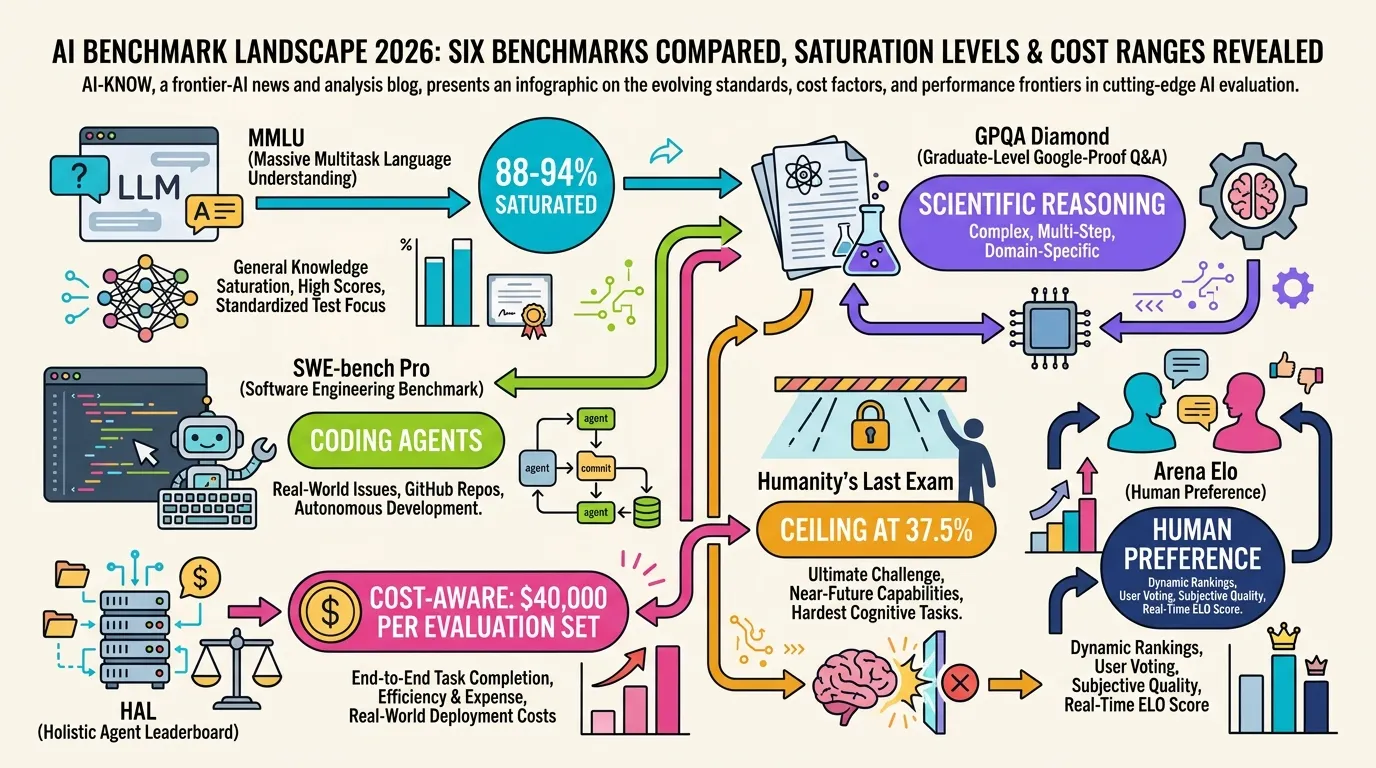
AI Evaluation in 2026: Beyond MMLU — A Practical Guide from SWE-bench Pro to HLE
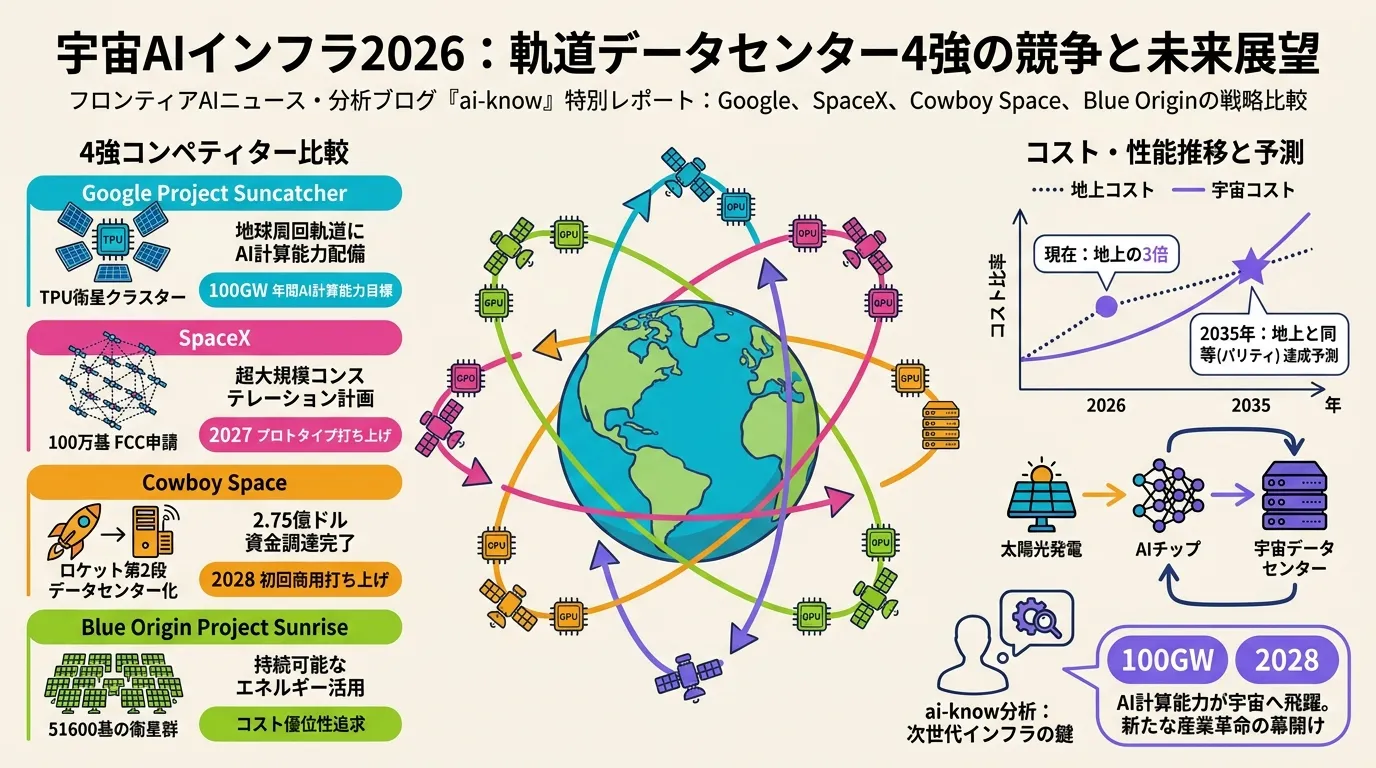
Space-Based AI Infrastructure 2026: Comparing Google, SpaceX, Cowboy Space, and Blue Origin in the Race to Orbit